
jueves, 18 de agosto de 2016
Cadenas de Markov (IV)
Si se regresa al ejemplo del inventario desarrollado en la sección anterior, es fácil ver que {Xt}, en donde Xt es el número de cámaras en el almacén al final de la semana t (antes de recibir el pedido), es una cadena de Markov. Se verá ahora cómo obtener las probabilidades de transición (de un paso), es decir, los elementos de la matriz de transición (de un paso)
miércoles, 17 de agosto de 2016
Cadenas de Markov (III)
o, en forma equivalente,

Ahora es posible definir una cadena de Markov. Se dice que un proceso estocástico (X1) (t = 0,1,......) es una cadena de Markov de estado finito si tiene las siguientes caracteristicas.

Ahora es posible definir una cadena de Markov. Se dice que un proceso estocástico (X1) (t = 0,1,......) es una cadena de Markov de estado finito si tiene las siguientes caracteristicas.
- Un número finito de estados
- La propiedad markoviana
- Probabilidad de transición estacionarias.
- Un conjunto de probabilidades iniciales P{Xo = i} para toda i.
miércoles, 3 de agosto de 2016
Cadenas de Markov (II)
Entonces se dice que las probabilidades de transición (de un paso) son estacionarias y por lo general se denotan por Pij. Así, tener probabilidades de transición estacionarias implica que las probabilidades de transición no cambian con el tiempo. La existencia de probabilidades de transición (de un paso) estacionarias también implica que, para cada i, j y n (n = 0, 1, 2, ....._.


martes, 2 de agosto de 2016
Cadenas de Markov (I)
Es necesario hacer algunas suposiciones sobre la distribución conjunta de X0, X1, ....., para obtener resultados analíticos. Una suposición que conduce al manejo analítico es que el proceso estocástico es una cadena de Markov (que se definirá más adelante), que tiene la siguiente propiedad esencial: se dice que un proceso estocástico {X1} tiene la propiedad markoviana si


lunes, 1 de agosto de 2016
Procesos Estocásticos (II)
Como ejemplo, considérese el siguiente problema de inventarios. Una tienda de cámaras tiene en almacén un modelo especial de cámara que se puede ordenar cada semana. Sean D1, D2,.....las demandas de esta camára durante la primera, segunda, ....., semana, respectivamente. Se supone que las Di son variables aleatorias independientes e idénticamente distribuidas que tienen una distribución de probabilidad conocida. Sea Xo el número de cámaras que se tiene en el momento de iniciar el proceso, X1 el número de cámaras que se tienen al final de la semana uno, X2 el número de cámaras al final de la semana dos, etc. Supóngase que Xo = 3. El sábado en la noche la tienda hace un pedido que le entregan en el momento de abrir la tienda el lunes. La tienda usa la siguiente politica (s, S) para ordenar: si el número de cámaras en inventario al final de la semana es menor que s = 1 (no hay cámaras) ordena (hasta) S = 3. De otra manera, no coloca la orden (si se cuenta con una o más cámaras en el almacén, no se hace el pedido). Se supone que las ventas se pierden cuando la demanda excede el inventario. Entonces, {Xt} para t = 0,1.... es un proceso estocástico de la forma que se acaba de describir. Los estados posibles del proceso son los enteros 0,1,2,3 que se representan el número posible de cámaras en inventario al final de la semana. De hecho, es claro que las variables aleatorias Xt son dependientes y se pueden evaluar en forma iterativa por medio de la expresión

para t = 0, 1, 2,.... Este ejemplo se usará con propósitos ilustrativos a lo largo de muchas de las secciones que siguen. La sección 15.3 define con más detalle el tipo de procesos estocásticos que se analizarán en este capítulo.

para t = 0, 1, 2,.... Este ejemplo se usará con propósitos ilustrativos a lo largo de muchas de las secciones que siguen. La sección 15.3 define con más detalle el tipo de procesos estocásticos que se analizarán en este capítulo.
domingo, 31 de julio de 2016
Procesos Estocásticos (I)
Un proceso estocástico se define sencillamente como una colección indexada de variables aleatorias {Xt}, en donde el índice t toma valores de un conjunto T dado. Con frecuencia T se toma como el conjunto de enteros no negativos y Xt representa una característica de interés medible en el tiempo t. Por ejemplo, el proceso estocástico, X1, X2, X3,....., puede representar la colección de niveles de inventario semanales (o mensuales) de un producto dado, o puede representar la colección de demandas semanales (o mensuales) de este producto.
Existen muchos procesos estocásticos interesantes. Un estudio del comportamiento de un sistema en operación durante algún periodo suele llevar al análisis de un proceso estocástico con la siguiente estructura. En puntos específicos del tiempo t etiquetados 0,1,......., el sistema se encuentra exactamente en una de un número finito de categorías o estados mutuamente excluyentes y exhaustivos, etiquetados 0,1,....,M. Los puntos en el tiempo pueden encontrarse a intervalos iguales o el espacio entre ellos pueden depender del comportamiento general del sistema físico en el que se encuentra sumergido el proceso estocástico, por ejemplo, el tiempo entre ocurrencias de algún fenómeno de interés. Aunque los estados pueden constituir una caracterización tanto cualitativa como cuantitativa del sistema, no hya pérdida de generalidad con las etiquetas numéricas 0,1,....,M, que se usarán en adelante para denotar los estados posibles del sistema. Así, la representación matemática del sistema físico es la de un proceso estocástico {Xt}, en donde las variables aleatorias se observan en t = 0, 1, 2,......, y en donde cada variable aleatoria puede tomar el valor de cualquiera de los (M + 1) enteros 0, 1,.....,M. EStos enteros son una caracterización de los (M + 1) estados del proceso. Debe hacerse notar que a cada estado que alcanza el proceso estocástico se le da una etiqueta que denota el estado físico del sistema. Es sólo por conveniencia en la notación que este conjunto se etiqueta 0,1,...., M.
Existen muchos procesos estocásticos interesantes. Un estudio del comportamiento de un sistema en operación durante algún periodo suele llevar al análisis de un proceso estocástico con la siguiente estructura. En puntos específicos del tiempo t etiquetados 0,1,......., el sistema se encuentra exactamente en una de un número finito de categorías o estados mutuamente excluyentes y exhaustivos, etiquetados 0,1,....,M. Los puntos en el tiempo pueden encontrarse a intervalos iguales o el espacio entre ellos pueden depender del comportamiento general del sistema físico en el que se encuentra sumergido el proceso estocástico, por ejemplo, el tiempo entre ocurrencias de algún fenómeno de interés. Aunque los estados pueden constituir una caracterización tanto cualitativa como cuantitativa del sistema, no hya pérdida de generalidad con las etiquetas numéricas 0,1,....,M, que se usarán en adelante para denotar los estados posibles del sistema. Así, la representación matemática del sistema físico es la de un proceso estocástico {Xt}, en donde las variables aleatorias se observan en t = 0, 1, 2,......, y en donde cada variable aleatoria puede tomar el valor de cualquiera de los (M + 1) enteros 0, 1,.....,M. EStos enteros son una caracterización de los (M + 1) estados del proceso. Debe hacerse notar que a cada estado que alcanza el proceso estocástico se le da una etiqueta que denota el estado físico del sistema. Es sólo por conveniencia en la notación que este conjunto se etiqueta 0,1,...., M.
miércoles, 27 de julio de 2016
Cadenas de Markov
En los problemas de toma de decisiones, con frecuencia surge la necesidad de tomar decisiones basadas en fenómenos que tienen incertidumbre asociado a ellos. Esta incertidumbre proviene de la variación inherente a las fuentes de esa variación que eluden el control o proviene de la inconsistencia de los fenómenos naturales. En lugar de manejar esta variabilidad como cualitativa, puede incorporarse al modelo matemático y manejarse en forma cuantitativa. Por lo general, este tratamiento se puede lograr si el fenómeno natural muestra un cierto grado de regularidad, de manera que sea posible describir la variación mediante un modelo probabílistico. Se supone aquí que el lector tiene conocimientos básicos sobre teoría de probabilidad. Las secciones que se presentan a continuación se refieren a los tipos especiales de modelos de probabilidad.
sábado, 9 de julio de 2016
Conclusiones Programación no lineal (II)
En los últimos años se ha tenido un gran interés en el desarrollo de paquetes de computadora (software) confiables y de alta calidad para el uso general en la aplicación del mejor de estos algoritmos por computadora. Por ejemplo, en el Systems Optimization Laboratory de la University of Stanford se cuenta con varios paquetes poderosos para computadora, como el MINOS. Estos paquetes son de uso común en otros centros para la solución de problemas de tipo que se presentó en este capítulo (al igual que de problemas de programación lineal). Las considerables mejoras que se han logrado, tanto en los algoritmos como en el software, permiten hoy día que algunos problemas grandes estén dentro de la factibilidad computacional.
Con el rápido crecimiento actual en el uso y potencial de las computadoras personales, se está logrando un buen progreso en el desarrollo de paquetes de programación no lineal para microcomputadoras. Por ejemplo, el paquete GAMS/MINOS (una combinación de dos programas bien conocidos para computadora grande) se encuentra ahora disponible para la computadora personal IBM. Otro paquete importante llamado GINO se desarrollo específicamente para microcomputadora.
La investigación en el campo de la programación no lineal sigue muy activa.
viernes, 8 de julio de 2016
Conclusiones Programación no lineal (I)
Los problemas prácticos de optimización con frecuencia incluyen un comportamiento no lineal que debe tomarse en cuenta. A veces es posible reformular las no linealidades para que se ajusten al formato de programación lineal, como se puede hacer con los problemas de programación separable. Sin embargo, es frecuente la necesidad de usar una formulación de programación no lineal.
Al contrario del caso del método símplex para programación lineal, no existe un algoritmo eficiente que se pueda utilizar para resolver todos los problema de programación no lineal. De hecho, algunso de estos problemas no se pueden resolver satisfactoriamente por ningún método, pero se han hecho grandes progresos en ciertas clases importantes de problemas que incluyen programación cuadrática, programación convexa y algunos tipos especiales de programación no convexa, Se dispone de una gran variedad de algoritmos que casi siempre tienen un buen desempeño en estos casos. Algunos de estos algoritmos incorporan procedimientos de alta eficiencia par la optimización no restringida en una parte de cada iteración y algunos emplean una sucesión de aproximaciones lineales o cuadráticas al problema original.
Al contrario del caso del método símplex para programación lineal, no existe un algoritmo eficiente que se pueda utilizar para resolver todos los problema de programación no lineal. De hecho, algunso de estos problemas no se pueden resolver satisfactoriamente por ningún método, pero se han hecho grandes progresos en ciertas clases importantes de problemas que incluyen programación cuadrática, programación convexa y algunos tipos especiales de programación no convexa, Se dispone de una gran variedad de algoritmos que casi siempre tienen un buen desempeño en estos casos. Algunos de estos algoritmos incorporan procedimientos de alta eficiencia par la optimización no restringida en una parte de cada iteración y algunos emplean una sucesión de aproximaciones lineales o cuadráticas al problema original.
jueves, 7 de julio de 2016
Resumen de la técnica secuencial de minimización no restringida - Ejemplo
Para ilustrar la técnica secuencial considérese el siguiente problema de dos variables




miércoles, 6 de julio de 2016
Resumen de la técnica secuencial de minimización no restringida - Paso iterativo y regla de detención (III)
La técnica secuencial de minimización no restringida se ha usado ampliamente por su simplicidad y versatilidad. Sin embargo, quienes se dedican al análisis numérico han encontrado que es bastante propenso a la inestabilidad numérica, así que se aconseja tomar precauciones extremas. Para mayor información sobre este tema, igual que sobre análisis similares para otros algoritmos, véase la referencia 7.
martes, 5 de julio de 2016
Resumen de la técnica secuencial de minimización no restringida - Paso iterativo y regla de detención (II)
Cuando no se satisfacen las suposiciones de programación convexa, este algoritmo debe repetirse varias veces a partir de las soluciones prueba distintas. El mejor de los máximos locales que se obtiene para el problema original es que debe usarse como la mejor aproximación disponible de un máximo global.
Por último, obsérvese que la técnica secuencial de minimización no restringida se puede extender de manera sencilla para manejar restricciones de igualdad gi(x) = bi. Una manera estándar es la siguiente. Para cada restricción de igualdad,

Por último, obsérvese que la técnica secuencial de minimización no restringida se puede extender de manera sencilla para manejar restricciones de igualdad gi(x) = bi. Una manera estándar es la siguiente. Para cada restricción de igualdad,

lunes, 4 de julio de 2016
Resumen de la técnica secuencial de minimización no restringida - Paso iterativo y regla de detención (I)

domingo, 3 de julio de 2016

sábado, 2 de julio de 2016
Programación no convexa - Técnica secuencial de miniización no restringida (V)
Por desgracia, no se puede dar una garantía para el error máximo cuando se trata de problemas de programación no convexa. Sin embargo, todavía es probable que rB(x) exceda el error real cuando x y x* son máximos locales correspondientes de P(x, r) y del problema original, respectivamente.
miércoles, 29 de junio de 2016
Programación no convexa - Técnica secuencial de miniización no restringida (IV)
Cuántos problemas son suficientes para permitir la extrapolación? Cuando el problema original satisface las suposiciones de programación convexa, se cuenta con información útil como guía en esta decisión. En particular, si x es un máximo global de P(x;r), entonces


martes, 28 de junio de 2016
Programación no convexa - Técnica secuencial de miniización no restringida (III)
Obsérvese que para valores factibles de x, el denominador de cada término es proporcional a la distancia de x a la frontera de restricciones para la restricción funcional o de no negatividad correspondiente. En consecuencia, cada término es un término de rechazo de frontera que tiene las tres propiedades anteriores, con respecto a esta frontera de restricción específica. Otra caracteristica atractiva de esta B (x) es que cuando se satisfacen todas las suposiciones de programación convexa, P(x; r) es una función cóncava.
Como B(x) mantiene la búsqueda lejos de la frontera de la región factible, una pregunta natural es: qué pasa si la solución que se quiere está ahí? Esta preocupación es la razón por la cual esta técnica incluye la solución de una sucesión de estos problemas de optimización no restringida para valores cada vez más pequeños de r que se acercan a cero (cuando la solución prueba final de cada uno se convierte en la solución prueba inicial del siguiente). Por ejemplo, cada nueva r se puede obtener a partir de la anterior al multiplicar por una constante θ (0 < θ < 1), en donde un valor usual es θ = 0.01. Acercarse r a cero, P(x,r) se acerca a f(x) de manera que el máximo local correspondiente de P(x;r) converge a un máximo local del problema original. Por ello, sólo es necesario resolver problemas de optimización no restringida, hasta que se puedan extrapolar sus soluciones a eta solución límite.
Como B(x) mantiene la búsqueda lejos de la frontera de la región factible, una pregunta natural es: qué pasa si la solución que se quiere está ahí? Esta preocupación es la razón por la cual esta técnica incluye la solución de una sucesión de estos problemas de optimización no restringida para valores cada vez más pequeños de r que se acercan a cero (cuando la solución prueba final de cada uno se convierte en la solución prueba inicial del siguiente). Por ejemplo, cada nueva r se puede obtener a partir de la anterior al multiplicar por una constante θ (0 < θ < 1), en donde un valor usual es θ = 0.01. Acercarse r a cero, P(x,r) se acerca a f(x) de manera que el máximo local correspondiente de P(x;r) converge a un máximo local del problema original. Por ello, sólo es necesario resolver problemas de optimización no restringida, hasta que se puedan extrapolar sus soluciones a eta solución límite.
lunes, 20 de junio de 2016
Programación no convexa - Técnica secuencial de miniización no restringida (II)
Así, si se inicia el procedimiento de búsqueda con una solución prueba inicial factible y después se intenta incrementar P(x; r), entonces B(x) proporciona una barrera que evita que la búsqueda curce (o llegue a) la frontera de la región factible del problema original.
La elección más natural para B(x) es

La elección más natural para B(x) es

domingo, 19 de junio de 2016
Programación no convexa - Técnica secuencial de miniización no restringida (I)
Como su nombre lo indica, esta técnica sustituye el problema original por una sucesión de problemas de optimización no restringida, cuyas soluciones convergen a una solución (máximo local) del problema original. Este enfoque es muy atractivo, que es mucho más sencillo resolver los problemas de optimización no restringida (véas el procedimiento de búsqueda del gradiente en la sección 14.5) que los que tienen restricciones. Cada uno de los problemas no restringidos de esta sucesión incluyen la sección de un valor estrictamente positivo (cada vez más pequeño) de un escalar r y después la obtención de x para


viernes, 17 de junio de 2016
Programación no convexa (II)
Un procedimiento de este tipo que se ha usado ampliamente desde su origen en la década de 1960 es la técnica de minimización no restringida secuencial. En realidad, existen dos versiones de esta técnica, una de las cuales es un algortimo de punto exterior que maneja soluciones no factibles y que al mismo tiempo utiliza una función de penalización para forzar la convergencia a la región factible. Se describirá la otra versión, que es un algoritmo de punto interior que tabaja directamente con soluciones factibles y que utiliza al mismo tiempo una función de barrera para forzarlas a mantenerse dentro de esa región factible. Aunque la técnica secuencial de minimización no restringida en un principio se presentó como una técnica de minización, se convertirá aquí en una técnica de maximización, con el fin de que sea consistente con el resto del capítulo. Se continuará suponiendo entonces, que el problema se encuentra en la forma dada al principio y que todas las funciones son diferenciables.
jueves, 16 de junio de 2016
Programación no convexa (I)
Las suposiciones de programación convexa son muy convenientes, pues aseguran que cualquier máximo local es también un máximo global. Desafortunadamente los problemas de programación no líneal en la práctica muchas veces apenas cumple estas suposiciones y de hecho tienen algunas disparidades menores. Qué tipo de enfoque conviene usar para manejar estos problemas de programación no convexa?
Una manera usual es aplicar un procedimiento de búsqueda algorítimico que se detenga cuando encuentre un máximo local y después reiniciarlo varias veces a partir de distintas soluciones pruebas iniciales, con el fin de encontrar cuantos máximos locales distintos sea posible. Se elige el mejor de estos máximos locales para llevarlo a la práctica. Por lo general, se usa un procedimiento de búsqueda planeado para encontrar un máximo global cuando se cumplen todas las suposiciones de programación convexa, pero que también puede encontrar un máximo local cuando no sea así.
miércoles, 15 de junio de 2016
Programación convexa - Resumen de algorimo de Frank-Wolfe - Ejemplo (IV)
En conclusión, se debe hacer notar que el algoritmo Frank-Wolfe es sólo un ejemplo de los algortimos de aproximación secuencial. Muchos de ellos utilizan aproximaciones cuadráticas en lugar de lineales en cada iteración, porque la aproximación cuadrática proporciona un ajuste mucho mejor al problema original y permite que la sucesión de soluciones converja mucho más rápidamente hacia la solución óptima que en caso de la figura 14.4b. Por esta razón, aun cuando el uso de los métodos de aproximación lineal secuencial, como el algoritmo de Frank-Wolfe, sea bastante sencillo, en general se prefieren los métodos de aproximación cuadrática Entre estos, los que más se usan son los métodos cuasi-Newton (o de variables métricas), que calculan una aproximación cuadrática a la curvatura de una función no lineal sin calcular explícitamente las segundas derivadas (parciales). (En los problemas de optimización linealmente restringida, esta función no lineal es la función objetivo, mientras que si se tienen restricciones no lineales, se trata de la función de Lagrange descrita en el apéndice 2.) Algunos algortimos cuasi-Newton no formularan ni resuelven siquiera, de manera explícita, una aproximación al problema de programación cuadrática en cada iteración; más bien incorporan algunos de los ingredientes básicos de los algoritmos de gradiente.
Para mayor información sobre la situación actual de los algoritmos de programación convexa.
martes, 14 de junio de 2016
Programación convexa - Resumen de algorimo de Frank-Wolfe - Ejemplo (III)
En la figura 14.14b se puede observar cómo las soluciones prueba adquieren valores de puntos alternados entre dos trayectorias que parecen intersecarse aproximadamente en el punto x = (1, 3/2). De hecho, este punto es la solución óptima, como se puede verificar si se aplican las condiciones KKT de la sección 14.6.
Este ejemplo ilustra una característica común del algoritmo de Frank-Wolfe: que las soluciones prueba alternan entre dos (o más) trayectorias. Cuando esto ocurre, se pueden extrapolar las trayectorias al punto aproximado en que se cruzan para estimar una solución óptima. Esta estimación tiende a ser mejor que usar la última solución prueba generada. Esto se debe a que la convergencia de las soluciones prueba hacia la solución óptima tiende a ser lenta y por ello es posible que la última solución esté todavía alejada del óptimo.
domingo, 12 de junio de 2016


sábado, 11 de junio de 2016

viernes, 10 de junio de 2016
Programación convexa - Resumen de algorimo de Frank-Wolfe - Ejemplo (I)
Considérese el siguiente problema de programación convexa linealmente restringido

jueves, 9 de junio de 2016

miércoles, 8 de junio de 2016
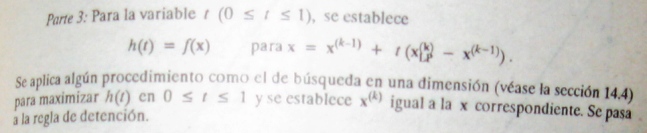
martes, 7 de junio de 2016
Programación convexa - Resumen de algorimo de Frank-Wolfe (II)
Parte 2: se encuentra una solución óptimo


domingo, 5 de junio de 2016
Programación convexa - Resumen de algorimo de Frank-Wolfe (I)
Paso inicial
Se encuentra una solución prueba factible inicial x^(0), por ejemplo, aplicando los procedimientos de programación líneal para encontrar una solución básica factible. Se hace k = 1
sábado, 4 de junio de 2016
Programación convexa - Un algoritmo (Frank-Wolfe) de aproximación lineal secuencial (II)
Después se aplica el método símplex (o el procedimiento gráfico, si n = 2) al problema de programación lineal que resulta a un de obtener su solución óptima xLP Nótese que la función objetivo lineal necesariamente se incrementa cuando se hace un recorrido sobre el segmento de la recta desde x' hasta xLP (que se encuentra en la frontera de la región factible); pero la aproximación lineal puede no ser buena para una x lejana a x', por lo que quizá la función objetivo no continuará creciendo durante toda la trayectoria desde x' hasta xLP. Así, en lugar de aceptar xLP como la siguiente solución prueba, se elige el punto sobre este segmento de recta que maximiza la función objetivo no lineal. Este punto se puede encontrar realizando una búsqueda en una dimensión con el procedimiento de la sección 14.4, en donde la única variable para los propósitos de sta búsqueda es la fracción t de la distancia total de x'a xLP. Este punto se convierte entonces en una nueva solución prueba para iniciar la siguiente iteraccióndel algoritmo, como se acaba de describir. La sucesión de soluciones prueba generados por las iteraciones converge a una solución óptima para problema original, de manera que el algoritmo se detiene en cuanto las soluciones prueba están los suficientemente cerca entre si como para poder concluir que se llegó a esta solución óptima.
viernes, 3 de junio de 2016
Programación convexa - Un algoritmo (Frank-Wolfe) de aproximación lineal secuencial
DAda una solución prueba factible x', la aproximación lineal que se usa para la función objetivo f(x) es la expansión de primer orden por series de Taylor, de f(x) alrededor de x = x', a saber:


jueves, 2 de junio de 2016
Programación convexa - Ejemplo aproximación secuencial
Como un ejemplo de algoritmo de aproximación secuencial se presentará el algoritmo de FRank-Wolfe para el caso de programación convexa linealmente restringida (de manera que las restricciones son Ax ≤ b, x ≥ 0, en forma matricial). Este procedimiento es bastante directo, combina aproximaciones lineales de la función objetivo (que permita usar el método símplex) con el procedimiento de búsqueda en una dimensión de la sección 14.4.
miércoles, 1 de junio de 2016
Programación convexa - los algorimos de aproximación secuencial
La tercera categoría, los algoritmos de aproximación secuencial, incluye métodos de aproximación lineal y aproximación cuadrática. Estos algoritmos constituyen la función objetivo no lineal por una sucesión de aproximaciones no lineales o cuadráticas. Para problemas de los algoritmos de programación lineal o cuadrática. Este trabajo se logra mediante otro análisis que conduce a una sucesión de solucioens que convergen a una solución óptima para el problema orginal. Aunque estos algoritmos son adecuados en especial para problemas de optimización linealmente restringida, algunos se pueden extender a problemas con funciones de restricción no lineales, si se usan las aproximaciones lineales adecuadas.
martes, 31 de mayo de 2016
Programación convexa - Algoritmos secuenciales no restringidos
La segunda categoría, los algoritmos secuenciales no restringidos, incluye los métodos de función de penalización y de función barrera. Estos algoritmos convierten el problema de optimización restringida original en una sucesión de problemas de optimización no restringida, cuyas soluciones óptimas convergen a la solución óptima del problema original. Cada uno de estos problemas de optimización no restringida se puede resolver por el procedimiento de búsqueda del gradiente de la sección 14.5. Esta conversión se logra al incorporar las restricciones a una función de penalización (o función barrera) que se resta de la función objetivo, con el fin de imponer un castigo grande a la violación de cualquier restricción (o aún al hecho de estar cerca de los límites). En la siguiente sección se verá un ejemplo de esta categoría de algoritmos.
sábado, 28 de mayo de 2016
Programación convexa - Algoritmos de gradientes
Una cateogoría la constituyenlos algoritmos de gradiente, en los que se modifica de alguna manrea el procedimiento de búsqueda del gradiente de la sección 14.5 para evitar que la trayectoria de búsqueda penetre la frontera de restricción. Por ejemplo, un método de gradiente popular es el método generalizado de gradiente reducido (CRG).
viernes, 27 de mayo de 2016
Programación convexa
En las secciones anteriores se presentaron algunos casos especiales de programación convexa no restringida, con función objetivo cuadrática y restricciones lineales y con funciones separables. También se vio, en la sección 14.6, una parte de la teoría para el caso general (condiciones necesarias y suficientes para la optimalidad). En esta sección se presentarán brevemente algunos tipos de enfoques usados para resolver el problema general de programación convexa (en donde la función objetivo f(x) que se va a maximizar es cóncava y las funciones de restricción gi(x) son convexas y después se presentará un ejemplo de un algoritmo para programación convexa.
No existe un algoritmo estándar único que se pueda usar siempre para resolver problemas de programación convexa. Se han construido muchos algoritmos diferentes, cada uno con ventaja y desventajas, y la investigación continúa activa en esta área. En términos generales, la mayor parte de estos algoritmos cae dentro de alguna de las tres categorias siguientes.
miércoles, 25 de mayo de 2016
Formulacion Propiedad esencial de programación separable - Extensiones (II)
Una deficiencia de la aproximación de funciones por medio de funciones lineales por partes que se describió en esta sección, es que sólo se logra una buena aproximacióncon un número muy grande de segmentos de recta (variables), mientras que una malla fina de intervalos nada más se necesita en la vecindad inmediata de la solución óptima. Se han desarrollado enfoques más elaborados que usan una sucesión de funciones líneales por partes de dos segmentos, para obtener aproximaciones cada vez más cercanas dentro de esta vecindad inmediata. Este tipo de enfoques tiende a ser tanto más rápido como más exacto al aproximar una solución óptima.
martes, 24 de mayo de 2016
Formulacion Propiedad esencial de programación separable - Extensiones (I)
Hasta ahora, la presentación se ha centrado en el caso especial de programación separable, en el que la única función no lineal es la función objetivo f(x). Ahora considérese brevementeel caso general en el que las funciones de restricción gi(x) no tienen que ser lineales, pero son convexas y separables, de manera que cada gi(x) se puede expresar como son una suma de funciones de variables individuales,

jueves, 4 de febrero de 2016
Formulacion Propiedad esencial de programación separable - Ejemplo (V)
Obsérvese que la mayor parte de las restricciones del modelo son retricciones de cota superior, esto es, restricciones que sólo especifican el máximo valor permitido para una variable individual. Cuando se dispone d eun paquete de computadora para una versión simplificada del método símplex que maneje este tipo de restricciones (véanse las secciones 7.5 y 9.1), de hecho se cuenta con una manera eficiente de resolver problemas de este tipo, aunque sean muy grandes.
miércoles, 3 de febrero de 2016
Formulacion Propiedad esencial de programación separable - Ejemplo (IV)
Por ejemplo, considérese la solución factible no aceptable x1R = 1, x1O = 1, x2R = 1, x2O = 3, que da una ganancia total Z = 13. La forma aceptable de lograr las mismas tasas de producción x1 = 2, x2 = 4 es x1R = 2, x1O = 0, x2R = 3, x2O =1. Esta última solución también es factible pero hace que el valor de Z aumente en (3-2)(1) + (5-1)(2) = 9.
De igual manera, la solución óptima para este modelo resulta ser x1R = 3, x1O = 1, x2R = 3, x2O = 0, que es una solución aceptable.
De igual manera, la solución óptima para este modelo resulta ser x1R = 3, x1O = 1, x2R = 3, x2O = 0, que es una solución aceptable.
martes, 26 de enero de 2016
Formulacion Propiedad esencial de programación separable - Ejemplo (III)
Con esto se llega a la propiedad esencial de programación separable. Si bien este modelo no toma en cuenta este factor de manera explícita, lo hace en forma implícita! Aunque el modelo tenga un exceso de soluciones "factibles" que en realidad son inaceptable, se garantiza que cualquier solución óptima será legítima, es decir, que no sustituirá tiempo de trabajo normal disponible con horas extra. (El razonamiento en este caso es análogo al del método de la M que se presentó en la sección 4.6, en el que también se permiten más soluciones factibles, pero no óptimas, de las reales por conveniencia para trabajar.) En efecto, se puede aplicar con seguridad el método símplex a este modelo para encontrar la mezcla de productos más redituable. La razón es doble. Primero, las dos variables de decisión para cada producto siempre aparecen juntas como una suma, (x1R + x1O) o (x2R + x2O), en cada restricción funcional (un en este caso) distinta a las restricciones de cota superior sobre las variables indiviaduales. Por tanto, siempre es posible convertir una solución factible no aceptable en una aceptable que tenga las mismas tasas de producción totales, x1 = x1R + x1O y x2 = x2R + x2O, con sólo reemplazar la producción en tiempo extra por producción normal lo más que se pueda. SEgundo, la producción en tiempo extra es menos redituable que la normal (es decir, la pendiente de cada curva de ganancia de la figura 15.13 es una función monótona decreciente de la tasa de producción), de modo que al convertir una solución factible no aceptable en una aceptable debe incrementarse la tasa total de la ganancia Z. En consecuencia, cualquier solución factible que usa tiempo extra de producción para un producto, cuando todavía se dispone de tiempo normal, no puede ser óptima respecto al modelo.
lunes, 25 de enero de 2016
Formulacion Propiedad esencial de programación separable - Ejemplo (II)
Sin embargo, existe un factor importante que no se toma en cuenta en esta formulación y éste es que no existe nada en el modelo que requiera que se utilice todo el tiempo normal disponible, antes de emplear cualquier tiempo extra para ese producto. En otras palabras, puede ser factible tener x10 > 0 aun cuando x1R < 3 y tener x20 > 0 aun cuando x2R < 3. Tal solución sería inaceptable para la gerencia. ( La prohibición de esta solución lleva a la reestricción especial de la que se hablaba)
miércoles, 20 de enero de 2016
Formulacion Propiedad esencial de programación separable - Ejemplo (I)
A primera vista puede parecer sencillo modificar el modelo de programación lineal de la Wyndor Glass Co. para que se ajuste a esta nueva situación. En particular, sea x1 = x1R + x1O la tasa de producción para el producto 1, en donde x1R es la tasa de producción alcanzada con tiempos normales de trabajo y x1O es la tasa de producci;on incremental al usar tiempo extra. Sea x2 = x2R + x2O definida de la misma manera para el producto 2. Así, n =2, n1 = 2 y n2 = 2 en el modelo general anterior. El nuevo problema de programación lineal trata de determinar los valores de x1R, x1O, x2R, x2O para

martes, 19 de enero de 2016
Propiedad esencial de programación separable - Ejemplo (II)
La administración ha tomado la decisión de usar tiempo extra en lugar de contratar más trabajadores durante esta situación temporal. Sin embargo, insiste en que se aprovechen por completo las brigadas de trabajo de cada producto en tiempo normal antes de usar cualquier tiempo extra. Lo que es más, piensa que temporalmente se deben cambiar las tasas de producción actuales (x1 =2 para el producto 1 y x2 = 6 para el producto 2), si esto mejora el rendimiento total. Por todo esto, ha girado instrucciones al departamento de investigación de operaciones para revisar los productos 1 y 2 y determinar de nuevo la mezcla de productos más redituables para los próximos cuatro meses.
sábado, 16 de enero de 2016
Propiedad esencial de programación separable - Ejemplo

viernes, 15 de enero de 2016
Propiedad esencial de programación separable (III)


jueves, 14 de enero de 2016
Propiedad esencial de programación separable (II)
Para escribir el modelo completo de programación lineal con la notación anterior, sea nj el número de segmentos de recta en fj(xj) (o en la función lineal por prtes que la aproxima), de manera que

miércoles, 13 de enero de 2016
Propiedad esencial de programación separable (I)
Cuando f(x) y gi(x) satisfacen las suposiciones de programación separable y cuando las funciones lineales por partes que resulta se ponen en la forma de funciones lineales, al eliminar la restricción especial se obtiene un modelo de programación lineal cuya solución satisface de manera automática la restricción especial.
Más adelante, en esta sección, se profundizara un poco más en la lógica que sustenta esta propiedad esencial, en el contexto del ejemplo específico.
Más adelante, en esta sección, se profundizara un poco más en la lógica que sustenta esta propiedad esencial, en el contexto del ejemplo específico.
martes, 12 de enero de 2016
Reformulación como un problema de programación lineal (II)
La restricción especial sólo permite la primera posibilidad, que es la única que da el valor correcto para fj(1).
Desafortunadamente, la restricción especial no se ajusta al formato requerido para las restricciones de programación lineal, y así algunas funciones lineales por partes no se pueden reescribir en el formato de programación lineal. Sin embargo, se supone que nuestra fj(xj) es cóncava, por lo que sj1 > sj2 > ....., y así, un algortimo para maximizar f(x) automáticamente asigna la prioridad más alta al uso de xj1 cuando (de hecho) se aumenta el valor de xj desde cero, la siguiente prioridad al uso de xj2, etc., sin incluir siquiera la restricción especial en forma explícita en el modelo. Esta observación conduce a la siguiente propiedad esencial.
Desafortunadamente, la restricción especial no se ajusta al formato requerido para las restricciones de programación lineal, y así algunas funciones lineales por partes no se pueden reescribir en el formato de programación lineal. Sin embargo, se supone que nuestra fj(xj) es cóncava, por lo que sj1 > sj2 > ....., y así, un algortimo para maximizar f(x) automáticamente asigna la prioridad más alta al uso de xj1 cuando (de hecho) se aumenta el valor de xj desde cero, la siguiente prioridad al uso de xj2, etc., sin incluir siquiera la restricción especial en forma explícita en el modelo. Esta observación conduce a la siguiente propiedad esencial.
lunes, 11 de enero de 2016
Reformulación como un problema de programación lineal (I)
La clave para dar una información lineal por partes la forma de una función lineal es usar variables separadas para cada segmento de recta. Para ilustrar esto, considérese la función lineal por partes fj(xj) que se muestra en la figura 14.12 caso 1 (o su aproximación en el caso 2), que tiene tres segmentos de recta en el intervalo de valores factibles de xj. Se introducen las tres nuevas variables, xj1, xj2, xj3, y se establece




domingo, 10 de enero de 2016
Programación separable (V)
Este tipo de situaciones puede conducir a cualquiera de las curvas de ganancia que se muestar en la figura 14.12. En el caso 1, la pendiente decrece a intervalos, de manera que fj(xj) es una función lineal por partes (una sucesión de segmentos de recta conectados). Para el caso 2, la pendiente puede decrecer en forma continua al crecer xj, de manera que fj(xj) es una función cóncava general. Cualquier función de este tipo se puede aproximar tanto como se quiera por una función lineal por aprtes y este tipo de aproximación se usa, según sea necesario, para problemas de programación separable. (La figura 14.12 muestra una función de aproximación que consiste en sólo tres segmentos de recta, pero la aproximación se puede mejorar si se introducen en intervalos.) Esta aproximación es muy conveniente, ya que una función lineal por partes de una sola variable se puede escribir como una función lineal de varias variables, con la restricción especial sobre estas variables que se describe a continuación.
sábado, 9 de enero de 2016
Programación separable (IV)
De manera que cada fj(xj) tiene una forma como la que se muestra en la figura 14.12 (cualquier caso), en el rango de valores factibles de xj. Como f(x) representa la medida de desempeño (por ejemplo, ganancia) de todas las actividades juntas, fj(xj) representa la contribución de la ganancia por parte de la actividad j cuando se realiza al nivel xj. La condición de que f(x) sea separable simplemente implica aditividad (véase la sección 3.3); esto es, no existe interacción entre las actividades (no se tienen términos de productos cruzados) que afecten la ganancia total más allá de sus contribuciones independientes. La suposición de que cada fj(xj) es cóncava indica que la ganancia marginal (pendiente de la curva de ganancia), se mantiene igual o decrece (nunca aumenta) conforme xj crece.
Las curvas cóncavas para la ganancia ocurren con mucha frecuencia. Por ejemplo, puede ser posible vender una cantidad limitada de algún producto a un cierto precio y después una cantidad adicional a un precio menor, y tal vez, otra cantidad adicional a un precio todavía menor. De igual manera, puede ser necesario comprar materias primas a fuentes cada vez más costosas. Otra situación común es aquélla en la que debe emplearse un proceso de producción más caro (como el uso de tiempo extra), para aumentar la tasa de producción sobre una cierta cantidad.
miércoles, 6 de enero de 2016

martes, 5 de enero de 2016
Programación separable (II)
Bajo las suposiciones anteriores, la función objetivo se puede expresar como una suma de funciones cóncavas de variables individuales,



Suscribirse a:
Comentarios (Atom)