La sección anterior presentó la forma en que se puede resolver una clas de problemas de programación no lineal mediante una extensión del méetodo símplex. Ahora se estudiará otra clase llamada programación separable, para la que de hecho se puede encontrar una aproximación tan cercana como se quiera, con un problema de programación lineal que tiene un número mayor de variables.
Como se indicó en la sección 14.3, la programación separable supone que la función objetivo f(x) es cóncava, que cada una de las funciones de restricción gi(x) es convexa y que todas estas funciones son funciones separables (funciones en las que cada término incluye una sola variable). Sin embargo, con el fin de simplificar la presentación, la atención de esta sección se centra en el caso especial en el que las funciones gi(x) convexas y separables de hecho son funciones lineales, como las de programación lineal. Así, solo la función objetivo requerirá un tratamiento especial.
sábado, 26 de diciembre de 2015
viernes, 25 de diciembre de 2015
Método Símplex Modificado - Ejemplo (IV)
La solución óptima que resulta para esta fase 1 del problema es x1 = 12, x2 = 9, u1 =3, con el resto de las variables iguales a cero. [El problema 43x pide que se verifique que esta solución es óptima demostrando que x1 = 12, x2 = 9, u1 = 3 satisfacen las condiciones KKT para el problema original, cuando se escriben en la forma dada en la sección 14.6] Entonces, la solución óptima para el problema de programación cuadrática (que sólo incluye la variable x1 y x2) es (x1,x2) = (12, 9)

jueves, 24 de diciembre de 2015
Método Símplex Modificado - Ejemplo (III)
La tabla 14.4 muestra los resultados de la aplicación del método símplex modificado a este problema. La primera tabla símplex exhibe el sistema de ecuaciones inicial después de convertir de minimización de Z a maximización de (-Z) y de eliminar algebraicamente las variables básicas iniciales de la ecuación (0), lo mismo que se hizo para el ejemplo de terapia de radiación en la sección 4.6. Las tres iteraciones procedenigual que en el método simplex normal, excepto por la eliminación de ciertos candidatos para la variable básica entrante, según la regla de entrada restringida. En la primera tabla se elimina u1 como candidato porque su variable complementaria (v1) es ya una variable básica (de todas maneras, habría entrado x2 puesto que -4 < - 3). En la segunda tabla se elimina tanto u1 como y2 (puesto que v1 y x2 son variables básicas) y de manera automática se elige x1 como único candidato con coeficientes negativos en el renglón 0 (mientras que el método símplex normal habría permitido la entrada o bien de x1 o de u1, porque están empatadas con el coeficiente más negativo). En la tercera tabla se eliminan y1 y y2 (porque x1 y x2 son variables básicas). Esta vez u1 no se elimina, pues v1 ya no es una variable básica, así que se elige u1 como variable entrante.
miércoles, 23 de diciembre de 2015
Método Símplex Modificado - Ejemplo (II)
La restricción de complementariedad adicional
no se incluye explícitamente, porque el algoritmo refuerza esta restricción de manera automática con la regla de entrada restringida. En particular, para cadauno de los tres pares de variables complementarias [(x1, y1), (x2, y2), (u1, v1)], siempre que una de las dos variables sea ya una variable básica, la otra se excluye de los candidatos como variable básica entrante. Como el conjunto inicial de variables básicas para el problema de programación lineal [z1, z2, v1] da una solución básica factible inicial que satisface la restricción de complementariedad, no hay manera de violar esta restricción con ninguna de las restricciones básicas factibles subsecuentes.
x1y1 + x2y2 + u1v1 = 0,
no se incluye explícitamente, porque el algoritmo refuerza esta restricción de manera automática con la regla de entrada restringida. En particular, para cadauno de los tres pares de variables complementarias [(x1, y1), (x2, y2), (u1, v1)], siempre que una de las dos variables sea ya una variable básica, la otra se excluye de los candidatos como variable básica entrante. Como el conjunto inicial de variables básicas para el problema de programación lineal [z1, z2, v1] da una solución básica factible inicial que satisface la restricción de complementariedad, no hay manera de violar esta restricción con ninguna de las restricciones básicas factibles subsecuentes.
martes, 22 de diciembre de 2015
Método Símplex Modificado - Ejemplo (I)
Se ilustrará este enfoque con el problema que se dio al principio de la sección. Como se puede verificar con los resultados del apéndice 1 [véase el problema 43a], f(x1, x2) es estrictamente cóncava; es decir

lunes, 21 de diciembre de 2015
Método Símplex Modificado - Regla de entrada restringida
Cuando se elige la variable básica entrante, se excluye de las posibilidades cualquier variable no básica cuya variable complementaria sea básica; la elección debe hacerse entre las otras variables no básicas, según el criterio normal del método símplex.
Esta regla conserva satisfecha la restricción de complementariedad en todo el curso del algoritmo. Cuando se obtiene una solución óptima.
Esta regla conserva satisfecha la restricción de complementariedad en todo el curso del algoritmo. Cuando se obtiene una solución óptima.
x*, u*, y*, v* z1 = 0,............................, zn = 0
para la fase I de este problema, x* es la solución óptima deseada para el problema original de programación cuadrática. La fase 2 del método de do fases no se necesita.
martes, 15 de diciembre de 2015
Método Símplex Modificado (III)
Después se utiliza la fase 1 del método de dos fases para encontrar una solución factible básica para el problema real; es decir, se aplica el método símplex (con una modificación) al siguiente problema de programación lineal.
 sujeta a las restricciones anteriores de programación lineal, obtenidas de las condiciones KKT, pero con estas variables artificiales incluidas.
sujeta a las restricciones anteriores de programación lineal, obtenidas de las condiciones KKT, pero con estas variables artificiales incluidas.
La modificación al método símplex es el siguiente cambio en el procedimiento para elegir una variable básica entrante.
La modificación al método símplex es el siguiente cambio en el procedimiento para elegir una variable básica entrante.
sábado, 7 de noviembre de 2015
Método Símplex Modificado (II)
Como se analizó en la sección 4.6, tal solución básica factible inicial se encuentra casi directamente. En el caso sencillo (poco probable) de que e^T ≤ 0 y b ≥ 0, las varibles básicas inciiales son los elementos de y y v (se multiplica por -1 todo el primer conjunto de ecuaciones), de manera que la solución deseada es x =0, u =0, y = -e^T, v = b. De otra manera, es necesario revisar el problema introducieno una variable artificial en cada una de las ecuaciones en donde cj > 0 (se agrega la variable a la izquierda) o bi < 0 ( se resta la variable a la izquierda y después se multiplican los dos lados por -1), con el fin de usar estas variables artificiales (que se denotan por z1, z2, etc) como varibles básicas iniciales para el problema revisado. (Nótese que esta selección de variables básicas iniciales satisface la restricción de complementariedad, ya que como variables básicas x = 0 y u = 0 de manera automática)
viernes, 6 de noviembre de 2015
Método Símplex Modificado (I)
El método símplex modificado explota el hecho importante de que, con excepción de la restricción de complementariedad, las condiciones KKT expresadas en la forma conveniente que se acaba de obtener, no son otra cosa que condiciones de programación lineal. Lo que es más la restricción de complementariedad sencillamente implica que no es permisible que las dos variables complementarias de un par dado sean variables básicas (las únicas variables > 0) al considerar soluciones básicas factibles (no generadas). Por tanto, el problema se reduce a encontrar una solución inicial básica factible para cualquier problema de programación lineal con estas restricción, sujeta a la restricción adicional sobre la identidad de las variables básicas. (Esta solución inicial básica factible puede ser la única solución factible en este caso.).
jueves, 5 de noviembre de 2015
Condiciones KKT para programación cuadrática (VI)
Como se supone que la función objetivo del problema original es cóncava y como las funciones de restricción son lineales y, por tanto, convexas, se puede aplicar el colorario del teorema de la sección 14.6. Así, x es óptima si y sólo si existen valores de y, y y v talse que los cuatro vectores juntos satisfagan todas estas condiciones. Así pues, el problema original se reduce al problema equivalente de encontrar una solución factible para estas restricciones.
Es interesante observar que este problema equivalente es un ejemplo del problema de complementariedad lineal introducido en la sección 14.3 (véase el problema 13), y que una restricción clave para este problema de complementariedad lineal es su restricción de complementariedad.
miércoles, 4 de noviembre de 2015
Condiciones KKT para programación cuadrática (V)
En cualquier problema de programación cuadrática, sus condiciones KKT se pueden reducir a la misma forma conveniente que contiene sólo restricciones de programación lineal y una restricción de complementariedad. En notación matricial, esta forma general es
 en donde los elementos del vector columna u son las ui de la sección anterior y lo elementos de los vectores columna y y v son variables de holgura.
en donde los elementos del vector columna u son las ui de la sección anterior y lo elementos de los vectores columna y y v son variables de holgura.
martes, 3 de noviembre de 2015
Condiciones KKT para programación cuadrática (IV)
Después de multiplicar las ecuaciones de las condiciones 1a y 1b por (-1) para obtener lados derechos no negativos, se obtiene la forma deseada para el conjunto completo de condiciones.
 Esta forma e en espcial conveniente ya que excepto por la restricción de complementariedad, estas condiciones son restricciones de programación lineal.
Esta forma e en espcial conveniente ya que excepto por la restricción de complementariedad, estas condiciones son restricciones de programación lineal.

lunes, 2 de noviembre de 2015
Condiciones KKT para programación cuadrática (III)
Para cada uno de estos tres pares, (x1, y1), (x2, y2), (u1, v1), las dos variables se llaman variables complementarias, porque sólo una de las dos puede ser diferente de cero. Como se requiere que las seis variables sean no negativas, estas nuevas formas de las condiciones 2a, 2b y 4 se pueden combinar en una restricción.
xiy1 + x2y2 + u1v1 = 0
llamada restricción de complementariedad
domingo, 1 de noviembre de 2015
Condiciones KKT para programación cuadrática (II)
Para poder reexpresar estas condiciones en una forma más conveniente, se mueven las constantes de las condiciones 1a, 1b y 3 al lado derecho y después se introducen variables de holgura no negativas (denotadas por y1, y2 y v1 respectivamente) para convertir estas desigualdades a ecuaciones.

sábado, 31 de octubre de 2015
Condiciones KKT para programación cuadrática (I)
Para que sea concreto, primero considérese el ejemplo anterior. Comenzando con la forma dada en la sección anterior, sus condiciones KKT son las siguientes

viernes, 30 de octubre de 2015
Programación cuadrática (II)

jueves, 29 de octubre de 2015
Programación cuadrática (I)
Como se indicó en la sección 14.3, el problema de programación cuadrática difiere del problema de programación lineal nada más en que la función objetivo incluye también términos xj² y xixj (i≠j). Así, si se usa la notación matricial comola que se introdujo en la sección 5.2, el problema es encontrar x para


miércoles, 28 de octubre de 2015
Ejemplo Teorema de Karush-Kuhn-Tucker (KKT) (IV)
Toda vez que se encontró una solución, no se considerarán casos adicionales.
En problemas más complicados que éste puede ser difícil, si no es materialmente imposible, derivar una solución óptima directa de las condiciones KKT. De todas maneras estas condiciones proporcionan información valiosa en cuanto a la identidad de una solución óptima y también permiten verificar que una solución propuesta sea óptima.
Existen mucha aplicaciones indirectas valiosas de las condiciones KKT. Una de ellas surge en la teoría de la dualidad desarrollada par programación no lineal, que se puede poner en parelelo con la teoría de la dualidad para programación líneal presentada en el capítulo 6. En particular, para cualquier problema de maximización restringida (llámese problema primal), se pueden usar las condiciones KKT para definir un problema dual asociado, que es un problema de minización restringido. Las variables del problema dual consisten en multiplicadores de Lagrange, ui = (i = 1,2,......, m) y las variables primales xj (j = 1,2....., n). En el caso especial de que el problema primal es un problema de programación lineal, las variables xj desaparecerán del problema dual y quedará el familiar problema dual de programación líneal (en el que las variables ui, aquí corresponden a las variables yi del capítulo 6). Cuando un problema primal es un problema de programación convexa, es posible establecer relaciones entre el problema primal y el problema dual, que son muy parecidas a las de programación lineal. Por ejemplo,la propiedad dualidad fuerte de la sección 6.1, que establece que los valore óptimos de las funciones objetivo son iguales, también se cumple aquí. Más aún, los valores de las variables ui en una solución óptima para el problema dual,de nuevo se pueden interpretar como los precios sombra (véanse las secciones 4.7 y 6.2); es decir, proporcionan la tasa a la que puede aumentar el valor óptimo de la función objetivo para el problema primal, si se aumenta (ligeramente) el lado derecho de la restricción correspondiente. Como la teoría de dualidad para programación no lineal es un tema relativamente avanzado se pide al lector interesado que consulte otros libros para obtener la información.
En la sección siguiente se verá otra aplicación indirecta de la condiciones KKT.
martes, 27 de octubre de 2015

lunes, 26 de octubre de 2015
Ejemplo Teorema de Karush-Kuhn-Tucker (KKT) (II)
A continuación se describen los pasos para resolver las condiciones KKT para este ejemplo específico.

domingo, 25 de octubre de 2015
Ejemplo Teorema de Karush-Kuhn-Tucker (KKT) (I)
Par ilustrar esta formulación y la aplicación de las condiciones KKT, considérese el siguiente problema de programación no lineal de dos variables.

sábado, 24 de octubre de 2015
Teorema de Karush-Kuhn-Tucker (KKT) (III) Corolario
Supóngase que f(x) es una función cóncava y que g1(x), g2(x), ......, gm(x) son funciones convexas (es decir, se trata de un problema de programación convexa) en donde todas estas funciones satisfacen las condiciones de regularidad. Entonces x* = (x1*, x2*,............xn* es una solución óptima si y sólo si se satisfacen todas las condiciones del teorema.
viernes, 23 de octubre de 2015
Teorema de Karush-Kuhn-Tucker (KKT) (II)
En las condiciones KKT anteriores, las ui corresponden a las variables dudales de programación lineal (al final de la sección se estudia más a fondo esta correspondencia) y tienen una interpretación económica comparable. (De hecho; las ui, surgieron en la derivación matemática, como los multiplicadores de Lagrange). Las condiciones 3 y 5 sólo ayudan a asegurar la factibilidad de la solución. Las otras condiciones eliminan la mayor parte de las soluciones factibles como posibles candidatos para ser la solución óptima. Debe hacerse notar que el cumplimiento de estas condiciones no garantiza que la solución sea óptima. Cómo se resume para obtener esta garantía. Estas suposiciones se establecen formalmente en la siguiente extensión del teorema.
jueves, 22 de octubre de 2015

miércoles, 21 de octubre de 2015
Condiciones de Karush-Kuhn-Tucker (KKT) para optimización restringida
La pregunta ahora es cómo reconocer una solución óptima para un problema de programación no lineal (con funciones diferenciables). Cuáles son las condiciones necesarias y (tal vez) suficientes que esa solución debe cumplir?;
En las secciones anteriores se hicieron notar estas condiciones para optimización no restringida, como se resume en los primeros dos renglones de la tabla 14.3. Al principio de la sección 14.3, también se expusieron estas condiciones para la ligera extensión de optimización no restringida cuando sólo se tienen restricciones de no negatividad. En la tabla 14.3 se muestran estas condiciones en el tercer reglón, en otra forma equivalente a la que sugiere la ampliación para optimización restringida general. Como se indica en el último renglón de la tabla, las condiciones para el caso general se llaman condiciones de Karush-Kuhn-Tucker (o condiciones KKT), porque fueron desarrolladas independientemente por Karush y por Kuhn y Tucker. Su resultado básico se expresa en el siguiente teorema.

En las secciones anteriores se hicieron notar estas condiciones para optimización no restringida, como se resume en los primeros dos renglones de la tabla 14.3. Al principio de la sección 14.3, también se expusieron estas condiciones para la ligera extensión de optimización no restringida cuando sólo se tienen restricciones de no negatividad. En la tabla 14.3 se muestran estas condiciones en el tercer reglón, en otra forma equivalente a la que sugiere la ampliación para optimización restringida general. Como se indica en el último renglón de la tabla, las condiciones para el caso general se llaman condiciones de Karush-Kuhn-Tucker (o condiciones KKT), porque fueron desarrolladas independientemente por Karush y por Kuhn y Tucker. Su resultado básico se expresa en el siguiente teorema.

martes, 20 de octubre de 2015
Resumen del procedimiento de búsqueda del gradiente - Ejemplo (V)
Si se quisiera minimizar la función objetivo f(x), un cambio en el procedimiento sería moverse en la dirección opuesta al gradiente en cada iteración; en otras palabras, la regla para obtener el siguiente punto sería.




lunes, 19 de octubre de 2015
Resumen del procedimiento de búsqueda del gradiente - Ejemplo (IV)
Sin embargo, como esta situación convergente de soluciones prueba nunca alcanza su límite, en realidad el procedimiento se detendrá en algún punto (dependiendo de ε) un poco antes de (1,1) como aproximación final de x*.
La figura 14.11 sugiere que el procedimiento de búsqueda del gradiente marca una trayectoria en zigzag hacia la solución óptima en lugar de moverse en línea recta. Tomando en cuenta este comportamiento, se han realizado algunas modificaciones que aceleran el movimiento hacia el óptimo.
Si f(x) no fuera una función cóncava, este procedimiento convergiría en un máximo local.
El único cambio en la descripción del procedimiento para este caso es que t* ahora corresponde al primer máximo local de f(x'+ t▽f(x'), conforme t aumenta su valor.
La figura 14.11 sugiere que el procedimiento de búsqueda del gradiente marca una trayectoria en zigzag hacia la solución óptima en lugar de moverse en línea recta. Tomando en cuenta este comportamiento, se han realizado algunas modificaciones que aceleran el movimiento hacia el óptimo.
Si f(x) no fuera una función cóncava, este procedimiento convergiría en un máximo local.
El único cambio en la descripción del procedimiento para este caso es que t* ahora corresponde al primer máximo local de f(x'+ t▽f(x'), conforme t aumenta su valor.
domingo, 18 de octubre de 2015
Resumen del procedimiento de búsqueda del gradiente - Ejemplo (III)
Una manera sencilla de organizar este trabajo es escribir una tabla como la que se muestra en la tabla 14.2, que resume las dos iteraciones anteriores. En cada iteración, la segunda columna muestra la solución prueba actual y la última muestra la nueva solución prueba eventual, que después se escribe abajo, en la segunda columna, para la siguiente iteración. La cuarta columna proporciona las expresiones para la xj en términos de t, que se tienen que sustituir en f(x) para dar la quinta columna.

sábado, 17 de octubre de 2015
Resumen del procedimiento de búsqueda del gradiente - Ejemplo (II)
También se puede verificar (véase el apéndice I) que f(x) es cóncava. Para comenzar el procedimiento de búsqueda del gradiente, supóngase que se elige x = (0,0) como solución prueba inicial. Como en este punto las respectivas derivadas parciales son 0 y 2, el gradiente es



viernes, 16 de octubre de 2015
Resumen del procedimiento de búsqueda del gradiente - Ejemplo (I)
Considérese el siguiente problema de dos variables


jueves, 15 de octubre de 2015
Resumen del procedimiento de búsqueda del gradiente (II)
Regla de detención
se evalúa ▽f(x') en x = x'. Se verifica si
miércoles, 14 de octubre de 2015
Resumen del procedimiento de búsqueda del gradiente
Paso inicial: se elige ε y cualquier solución prueba incial x'. Se pasa primero a la regla de detención.


martes, 13 de octubre de 2015
Procedimiento de búsqueda del gradiente (III)
Por lo general, la parte más difícil del procedimiento de búsqueda del gradiente es encontrar t*, el valor de t que maximiza f en la dirección del gradiente, en cada iteracción. Como x y ▽f(x) tienen valores fijos para la maximización y como f(x) es cóncava, este problema se debe ver como el de maximizar una función cóncava de una sola variable t. En efecto, se puede resolver con el procedimiento de búsqueda en una dimensión de la sección 14.4 (en donde la cota inferior inicial sobre t debe ser no negativa por la restricción de t ≥ 0). De otra manera, si f e una función simple, es posible que e pueda obtener una solución analítica estableciendo la derivada con respecto a t igual a cero y depejando.
lunes, 12 de octubre de 2015
Procedimiento de búsqueda del gradiente (II)
Una anología puede ayudar a aclarar este procedimiento. Supóngase que una persona quiere subir a la cumbre de una montaña. Esta persona es miope y no puede ver la cumbre para caminar en esa dirección, pero cuando se detiene, puede ver el piso a su alrededor y determinar la dirección en la que la pendiente de la montaña es más pronunciada. La persona puede caminar en línea recta. Mientras camina, también es capaz de percibir cuándo ya no va hacia arriba (pendiente cero en esa dirección). Suponiendo que la montaña es cóncava, el individuo puede usar el procedimiento de búsqueda del gradiente para escalar hasta la cima eficientemente. Este problema tiene dos variables, en donde (x1, x2) representa las coordenadas (ignorando la altura) de la localización actual. La función f(x1, x2) da la altura de la montaña en (x1, x2). La persona comienza cada iteración en su localización actual (solución prueba actual) al determinar la dirección [en el sistema de coordenadas (x1, x2)] en la que la montaña tiene la mayor pendiente (la dirección del gradiente) en este punto. Después, comienza a caminar en otra dirección fija y continúa haciéndolo mientras sigue subiendo. Luego se detiene en una nueva localización (solución) prueba, cuando la montaña se nivela en la dirección en que camina. Estas iteraciones continúan, siguiendo una trayectoria en zig-zag hacia arriba, hasta que e alcanza una localización prueba en la que la pendiente es esencialmente cero en todas direcciones. Bajo la suposición de que la montaña [f(x1, x2)] es cóncava, en principio, la persona debe estar en la cima de la montaña.
domingo, 11 de octubre de 2015
Procedimiento de búsqueda del gradiente (I)
Pueto que el problema en cuestión no tiene restricciones, esta interpretación del gradiente sugiere que un procedimiento de búsqueda eficientes debe moverse en la dirección del gradiente hasta que (en esencia) alcance una solución óptima x*, en la que ▽f(x*) = 0. Sin embargo, no resultaría práctica cambiar x continuamente en la dirección de ▽f(x), ya que esta serie de cambios requeriría una reevaluación continua de ∂f/∂xj y del cambio de dirección de la trayectoria. Entonces, una mejora forma de hacerlo es continuar el movimiento en una dirección fija a partir de la solución prueba actual, sin detenerse, hasta que f(x) deje de aumentar. Este punto de detención sería la siguiente solución prueba, por lo que se debe volver a calcular el gradiente para determinar la nueva dirección de movimiento. Con este enfoque, cada iteración incluye cambiar la solución prueba actual x'como sigue:




sábado, 10 de octubre de 2015
Optimización no restringida de varias variables (III)
Como se supone que la función objetivo f(x) es diferenciable, posee un gradiente denotado por ▽f(x) en cada punto x. En particular, el gradiente en un punto específico x = x' es el vector cuyos elementos son las derivadas parciales respectivas evaluadas en x = x', de manera que


viernes, 9 de octubre de 2015
Optimización no restringida de varias variables (II)
En la sección 14.4 se usó el valor de la derivada ordinaria para elegir una de sólo dos direcciones posibles (aumentar x o disminuir x) para pasar de la solución prueba actual a la siguiente. La meta era alcanzar en algún momento un punto en el que la derivada fuera (esencialmente) cero. Ahora se tienen innumerables direcciones posibles hacia dónde moverse; corresponden a las tasas proporcionales posibles a las cuales las respectivas variables pueden cambiar. La meta es alcanzr eventualmente un punto en el qeu todas las derivadas parciales sean (en esencia) cero. Por tanto, la extensión del procedimiento de búsqueda en una dimensión requiere emplear los valores de las derivadas parciales para seleccionar la dirección específica en la que conviene moverse. Esta selección implica el uso del gradiente dela función objetivo, como se describirá en seguida.
jueves, 8 de octubre de 2015
Optimización no restringida de varias variables (I)
Ahora considerese el problema de maximizar una función cóncava f(x) de varias variables (o de variables múltiples), x = (x1, x2,......., xn) en la que no se tiene retricciones sobre los valores factibles. Supóngase de nuevo que la condición necesaria y suficiente para la optimalidad, dada por el sistema de ecuaciones que se obtiene al establecer las repectivas derivadas praciales iguales a cero, no e puede resolver análiticamente, por lo que debe emplearse un procedimiento de búsqueda númerico. Cómo puede extenderse el procedimiento de búsqueda en una dimensión a este problema multidimensional??.
miércoles, 7 de octubre de 2015
Procedimiento de búsqueda en una dimensión - Paso inicial Ejemplo (II)
Como la segunda derivada es no positiva en todos lados, f(x) es una función cóncava, y el procedimiento de búsqueda se aplica sin problemas para encontrar su máximo global. Una rápida inspección a esta función (sin construir siquiera la gráfica de la figura 14.10) indica que f(x)es positiva para valores pequeños de x, pero es negativa para x < 0 o x > 2. Entonces, x(barra abajo) = 0 y x(barra arriba) =2 se pueden usar como cotas iniciales, con su punto medio x' = 1, como solución prueba inicial. Sea 0.01 la tolerancia del error para x* en la regla de detención, de manera que (x(barra arriba) - x(barra abajo)) ≤ 0.02 con la x'final en el punto medio. Al aplicar el procedimiento de búsqueda en una dimensión se obtiene la sucesión de resultados que se muestranen la tabla 14.1 [Esta tabla incluye tanto los valores de la función como los de la derivada, para información del lector, en donde la derivada se evalúa en la solución prueba que se genera en la interación anterior. Obsérvese que, de hecho, el algoritmo no necesita calcular f(x') y que sólo tiene que calcular la derivada hasta el punto en que se pueda determinar su signo]. La conclusión es que
x* ≈ 0.836
0.828125 < x* < 0.84375

martes, 6 de octubre de 2015
Procedimiento de búsqueda en una dimensión - Paso inicial Ejemplo (I)
Supóngase que la función que se quiere maximizar es


lunes, 5 de octubre de 2015
Procedimiento de búsqueda en una dimensión - Paso inicial
Se selecciona ε. Se encuentan x(barra abajo) y x(barra arriba) iniciales por inspección ( o encontrado valores respectivos de x en los cuales la derivada sea positiva y luego negativa). Se elige una solución prueba inicial.


domingo, 4 de octubre de 2015
Procedimiento de búsqueda en una dimensión (III)
Aunque existen varias reglas razonables para elegir cada nueva solución prueba, la que se usa en el siguiente procedimiento es la regla del punto medio (tradicionalmente llamada plan de búsqueda de Bolzano), que dice que se seleccione el punto medio entre la dos cotas actuales.
Resume el procedimiento de búsqueda en una dimensión.
sábado, 3 de octubre de 2015
Procedimiento de búsqueda en una dimensión (II)
La idea que fundamenta el procedimiento de búsquedaen una dimensión es muy intuitiva; se basa en el hecho de que la pendiente (derivada) esa positiva o negativa en una solución prueba, en definitiva indica si es necesario hacer esta solución más grande o más chica para moverse hacia una solución óptima. Así, si la derivada evaluada para un valor específico de x es positiva, entonces x* debe ser más grande queesta x (véase la figura 1439), con lo que x se convierte en una cota inferior para las soluciones prueba que en adelante se tomarán en cuenta.
Por el contrario, si la derivada es negativa, entonces x* debe ser más chica que esta x, y x se convierte en una cota superior. Una vez que se han indentificado ambas cotas, cada nueva solución prueba que se selecciona entre ellas proporciona una nueva cota más estrecha de uno de los dos tipos, cerrando la búsqueda cada vez más. Siempre y cuando se usa una regla razonable para elegir cada solución prueba en esta forma, la sucesión de soluciones prueba debe converger a x*. En la práctica, esto significa continuar la sucesión, hasta que la distancia entre las cotas sean lo suficientemente pequeña como para que la siguiente solución prueba se encuentre dentro de una tolerancia de error de x* preespecificada.
En eguida se resume este proceso completo, usando la notación


Por el contrario, si la derivada es negativa, entonces x* debe ser más chica que esta x, y x se convierte en una cota superior. Una vez que se han indentificado ambas cotas, cada nueva solución prueba que se selecciona entre ellas proporciona una nueva cota más estrecha de uno de los dos tipos, cerrando la búsqueda cada vez más. Siempre y cuando se usa una regla razonable para elegir cada solución prueba en esta forma, la sucesión de soluciones prueba debe converger a x*. En la práctica, esto significa continuar la sucesión, hasta que la distancia entre las cotas sean lo suficientemente pequeña como para que la siguiente solución prueba se encuentre dentro de una tolerancia de error de x* preespecificada.
En eguida se resume este proceso completo, usando la notación
viernes, 2 de octubre de 2015
Procedimiento de búsqueda en una dimensión (I)
Al igual que otros procedimientos de búsqueda para programación no lineal, éste trata de encontrar una serie de soluciones prueba que conduzcan hacia una solución óptima. En cada iteración, se comienza con la solución prueba actual para llevar a cabo una búsqueda sistemática, que culmina con la identificación de una nueva solución prueba mejorada (se esperaque sustancialmente mejorada)
jueves, 1 de octubre de 2015
Optimización no restringida de una variable (I)
Se comenzará por explicar cómo se pueden resolver algunos tipos de problemas como los que se acaban de describir, considerando el caso más sencillo, la optimización no restringida con una sola variable x(n=1), en donde la función diferenciable f(x) que debe maximizarse es cóncava. Así, la condición necesaria y sufiente para que una solución particularx = x* sea óptima (un máximo global) es
como se bosqueja en la figura 14.9. Si en esta ecuación se puede despejar directamente x*, el problema llegó a su fin, pero si f(x) no e una función sencilla y su derivada no es una función lineal o cuadrática, tal vez sea imposible resolver la ecuación analíticamente. De ser así, el procedimiento de búsqueda en una dimensión proporcionauna forma directa de resolverlo númericamente.

df/dx = 0 en x = x*
como se bosqueja en la figura 14.9. Si en esta ecuación se puede despejar directamente x*, el problema llegó a su fin, pero si f(x) no e una función sencilla y su derivada no es una función lineal o cuadrática, tal vez sea imposible resolver la ecuación analíticamente. De ser así, el procedimiento de búsqueda en una dimensión proporcionauna forma directa de resolverlo númericamente.
miércoles, 30 de septiembre de 2015
Problema de complementariedad (III)
Un caso espcialmente importante es el problema de complementariedad lineal en el que
F(x) = q + Mz.
en donde q es un vector columna dado y M es una matriz p x p dada. Se dispone de algoritmos eficientes para resolver este problema bajo algunas suposiciones adecuadas sobre las propiedades de la matriz M. Uno de estos requiere pivotear de una solución básica factible a la siguiente, en forma muy parecida a la del método símplex para programación lineal.
Además de tener aplicaciones en programación no lineal, los problemas de complementariedad se utilizan en teoría de juegos, problemas de equilibrio económico y problemas de equilibrio en ingeniería.
martes, 29 de septiembre de 2015
Problema de complementariedad (II)
Aquí, w y z son vectores columna, F es una función con vlores vectoriales dada y el superíndice T denota traspuesta (véase el apéndice 3). El problema no tiene función objetivo, de manera que técnicamenta no es un problema de programación no lineal completo. Se llama problema de complementariedad por las relaciones complementarias que establecen que una de las dos
wi = 0 o zi = 0 (o ambas) para cada i = 1, 2, ....., p
wi = 0 o zi = 0 (o ambas) para cada i = 1, 2, ....., p
lunes, 28 de septiembre de 2015
Problema de complementariedad (I)
Cuando se estudie la programación cuadrática en la sección 14.7, se verá un ejemplo de cómo la resolución de ciertos problemas de programación no lineal se puede reducir a resolver el problema de complementariedad. Dadas las variables w1, w2,........, wp y z1, z2......., zp, el problema de complementariedad encuentra una solución factiblepara el conjunto de restricciones.
Que tambien satisface la restricción de complementariedad
w = F(z) w ≤ 0, z ≥ 0,
Que tambien satisface la restricción de complementariedad
w^Tz =0
domingo, 27 de septiembre de 2015
Tipos de problemas de programación no lineal - Programación Fraccional (II)
Cuando se puede hacer, el enfoque más directo para resolver un problema de programación fraccional es transformarlo enun problema equivalente de algún tipo estándar que disponga de un procedimiento deficiente. Para ilustar esto, supóngase que f(x) es de la forma de programa-ción fraccional lineal.
 que se puede resolver con el método símplex. En términos generales, se puede usar el mismo tipo de transformación para convertir un problema de programación fraccional con f1(x) cóncava, f2(x) convexa y gi(x) convexas, en un problema equivalente de programación convexa.
que se puede resolver con el método símplex. En términos generales, se puede usar el mismo tipo de transformación para convertir un problema de programación fraccional con f1(x) cóncava, f2(x) convexa y gi(x) convexas, en un problema equivalente de programación convexa.

sábado, 26 de septiembre de 2015
Tipos de problemas de programación no lineal - Programación Fraccional (I)
Supóngase que la función objetivo se encuentra en la forma de una fracción, esto es, la razón o cociente de dos funciones.
Maximizar f(x) = f1(x)/f2(x)
Estos problemas de programación fraccional surgen, por ejemplo, cuando se maximiza la razón de la producción entre la horas-hombre empleadas (productividad), o la ganancia entre el capital invertido (tasa de crecimiento), o el valor esperado entre la desviación estandar de alguna medida de desempeño para una cartera de inversiones (rendimiento/riesgo). Se han formulado algunos procedimientos de solución especiales para ciertas formas de f1(x) y f2(x).
Maximizar f(x) = f1(x)/f2(x)
Estos problemas de programación fraccional surgen, por ejemplo, cuando se maximiza la razón de la producción entre la horas-hombre empleadas (productividad), o la ganancia entre el capital invertido (tasa de crecimiento), o el valor esperado entre la desviación estandar de alguna medida de desempeño para una cartera de inversiones (rendimiento/riesgo). Se han formulado algunos procedimientos de solución especiales para ciertas formas de f1(x) y f2(x).
viernes, 25 de septiembre de 2015
Tipos de problemas de programación no lineal - Programación geométrica (II)
En tales casos, las ci y aij representan las constantes físicas y las xj son las variables de diseño. EStas funciones por lo general no son ni cóncavas ni convexas, con lo que no se pueden aplicar las técnicas de programación convexa. Sin embargo, existe un caso importante en el que el problema se pueda transformar en un problema de programación convexa equivalente. Este caso es aquél en el que todos los coeficientes ci en cada función son estrictamente positivos, es decir, las funciones son polinomios positivos generalizados (ahora llamados posinominales), y la función objetivo se tiene que minimizar. El problema equivalente de programación convexa con variables de decisión yi, y2,......yn se obtiene entonces al establecer.
 en todo el modelo orifinal, y se puede aplicar un algoritmo de programación convexa. Se cuenta con otro procedimiento de solución para resolver estos problemas de programación posinomial, al igual que para problemas de programación geométrica de otros tipos.
en todo el modelo orifinal, y se puede aplicar un algoritmo de programación convexa. Se cuenta con otro procedimiento de solución para resolver estos problemas de programación posinomial, al igual que para problemas de programación geométrica de otros tipos.

jueves, 24 de septiembre de 2015
Tipos de problemas de programación no lineal - Programación geométrica (I)
Cuando se aplica programación no lineal a problemas de diseño de ingeniería, muchas veces la función objetivo y las funciones de restricción toman la forma


miércoles, 23 de septiembre de 2015
Tipos de problemas de programación no lineal - Programación no convexa
La programación no convexa incluye todos los problemas de programación no lineal que no satisfacen las suposiciones de programación convexa. En este caso, aun cuando se tenga éxito en encontrar un máximo local, no hay garantía de que sea también un máximo global. Así, no se tiene un algoritmo que garantice encontrar una solución óptima para todos estos problemas; pero sí existen algunos algoritmos bastantes adecuados para encontrar máximos locales, en especial cuando las formas de las funciones no lineales no se desvían demasiado de aquéllas que se supusieron para programación convexa. En la sección 14.10 se presenta un algoritmo para estos problemas.
Ciertos tipso específicos de problemas de programación no convexa se pueden resolver sin mucha dificultad mediante métodos especiales. Dos de ellos, de gran importancia, se presentarán mmás adelante.
Ciertos tipso específicos de problemas de programación no convexa se pueden resolver sin mucha dificultad mediante métodos especiales. Dos de ellos, de gran importancia, se presentarán mmás adelante.
martes, 22 de septiembre de 2015
Tipos de problemas de programación no lineal - Programación Separable
La programación separable es un caso especial de programación convexa, en donde la suposición adicional es
3. Todas la funciones f(x) y gi(x) son funciones separables.
Una función separable es una función en la que cada término incluye una sola variable, por lo que la función se puede separar en una suma de funciones de variables individuales. Por ejemplo, si f(x) es una función separable, se puede expresar como

en donde cada fj(xj) incluye sólo los términos con xj. En la terminología de programación lineal (véase la sección 3.3) , los problemas de programación separable satisfacen las suposiciones de aditividad pero no las de proporcionalidad (para funciones no lineales).
Es importante distinguir estos problemas de otros de programación convexa, ya que cualquier problema de programación separable se puede aproximar muy de cerca mediante uno de programación lineal y, entonces, se puede aplicar el eficiente método símplex. Este enfoque se describe en la sección 14.8 (Para simplificar, se centra la atención en el caso linealmente restringido, en el que el tratamiento especial se necesita nada más para la función objetivo.)
lunes, 21 de septiembre de 2015
Tipos de problemas de programación no lineal - Programación Convexa
La programación convexa abarca una amplia clase de problemas entre los que se encuentran como casos especiales, todos los tipos anteriores cuando f(x) es cóncava. Las suposiciones son
1. f(x) es cóncava
2. Cada una de las gi(x) son convexas.
Como se dijo al final de la sección 14.2, estas suposiciones son suficientes para asegurar que un máximo local es un máximo global. En la sección 14.6 se verá que las condiciones y suficientes para obtener tal solución óptima son una generalización natural de las condiciones que se acaban de exponer para la optimización no restringida y su extensión a la inclusión de restricciones de no negatividad. La sección 14.9 describe los enfoques algorítmicos para resolver problemas de programación convexa.
domingo, 20 de septiembre de 2015
Tipos de problemas de programación no lineal - Programación Cuadrática
DE nuevo los problemas de programación cuadrática tienen restricciones lineales, pero ahora la función objetivo f(x) debe ser cuadrática. Entonces, la única diferencia entre éstos y un programa de programación lineal es que algunos términos de la función objetivo incluyen el cuadrado de una variable o el producto de dos variables.
Se han desarrollado muchos algoritmos para este caso, con la suposición adicional de que f(x) es cóncava. La sección 14.7 presenta un algoritmo que maneja una extensión del método símplex.
La programación cuadrática es muy importante, en parte porque las formulaciones de este tipo surgen de manera natural en muchas aplicaciones. Por ejemplo, el problema de la selección de una cartera con inversiones riesgosas, descrito en la sección 14.1 se ajusta a este formato. Sin embargo, otra razón por la que es importante es que al resolver problemas generales de optimización linealmente restringida se puede obtener la solución de una sucesión de aproximaciones de programación cuadrática.
sábado, 19 de septiembre de 2015
Tipos de problemas de programación no lineal - Optimización linealmente restringida
Los problemas de optimización linealmente restringida se caracterizan por restricciones que se ajustan completamente a la programación líneal, de manera que todas las funciones de restricción gi(x) son lineales, pero la función objetivo es no lineal. El problema se simplifica mucho si sólo se tien que tomar en cuenta una función no lineal y una región factible de programación lineal. Se han desarrollado varios algortimos especiales basados en una extensión del método símplex para analizar la función objetivo no lineal.
Un caso especial importante es la programación cuadrática.
viernes, 18 de septiembre de 2015
Tipos de problemas de programación no lineal - Optimización no restringida (II)
Cuadno f(x) es cóncava, esta condición tambien es suficiente, con lo que la obtención de x* se reduce a resolver el sistema de las n ecuaciones obtenidas al establecer las n derivadas parciales iguales a cero. Por desgracia, cuando se trata de funciones no lineales f(x), estas ecuaciones suelen ser no lineales también, en cuyo caso es poco probable que se pueda obtener analíticamente su solución simultánea. Qué se puede hacer en este caso? Las secciones 14.4 y 14.5 describen procedimientos algorítmicos de busqueda para encontrar x*, primero para n =1 y luego para n > 1. Estos procedimientos también juegan un papel importante en la solución de muchos tipos de problemas con restricciones, que se describirán en seguida. La razón es que muchos algoritmos pra problemas restringidos están construidos de forma que se adaptan a versiones no restringidas del problema en una parte de cada iteración.
Cuando una vriable xj tiene una restricción de no negatividad, xj ≥ 0, la condición necesaria (y tal vez) suficiente anterior cambi ligeramente a:

Cuando una vriable xj tiene una restricción de no negatividad, xj ≥ 0, la condición necesaria (y tal vez) suficiente anterior cambi ligeramente a:

jueves, 17 de septiembre de 2015
Tipos de problemas de programación no lineal - Optimización no restringida (I)
Los problemas de optimización no restringida no tienen restricciones, por lo que la función objetivo es sencillamente
Maximizar f(x)
sobre todos los valores x = (x1, x2,.......xn). Según se repasa en el apéndice 2, la condición necesaria para que una solución específica x = x* sea óptima cuando f(x) es una función diferenciable es:
∂f/∂xj = 0 en x = x*, para j = 1,2,.....,n.
Maximizar f(x)
sobre todos los valores x = (x1, x2,.......xn). Según se repasa en el apéndice 2, la condición necesaria para que una solución específica x = x* sea óptima cuando f(x) es una función diferenciable es:
∂f/∂xj = 0 en x = x*, para j = 1,2,.....,n.
miércoles, 16 de septiembre de 2015
Tipos de problemas de programación no lineal
Los problemas de programación no lineal se presentan de muchas formas distintas. Al contrario del método simplex para programación lineal, no se dispone de un algoritmo que resuelva todos estos tipos especiales de problemas. En su lugar, se han desarrollado algoritmos para algunas clases (tipos especiales) de problemas de programación no lineal. Se introducirán las clases más importantes y después se describirá cómo se pueden resolver algunos de estos problemas.
martes, 15 de septiembre de 2015
Ilustración gráfica de problema de programación no lineal (VI)
Si un problema de programación no lineal no tiene restricciones, el hecho de que la función objetivo esa cóncava garantiza que un máximo local es un máximo global. (Una función objetivo convexa asegura que un mínimo local es un mínimo global). Si existen restricciones, entonces se necesita una condición más para dar esta garantía. Esta es que la región, factible sea un conjunto convexo. Como se analiza en el ápendice 1, un conjunto convexo es un conjunto de puntos tales que, para cada par de puntos de la colección, el segmento de recta que los une está totalmente contenido en la colección. Así, la región factible en el problema de la Wyndor Glass Co. en la figura 3.3 (o la región factible para cualquier otro problema de programación lineal) es un conjunto convexo. De igual manera, la región factible de la figura 14.5 también es un conjunto convexo; esto ocurre siempre que todas las gi(x) [para las restricciones gi(x) ≤ bi] son convexas. Entonces,para garantizar que un máximo local es un máximo global en un problema de programación no lineal con restricciones gi(x) ≤ bi (i = 1, 2,......,m) y x ≥ 0, la función objetivo f(x) debe ser cóncava y cada gi(x) debe ser convexa.
lunes, 14 de septiembre de 2015
Ilustración gráfica de problema de programación no lineal (V)
Una función de este tipo cuya curvatura siempre es "hacia abajo" (o que no tiene curvatura) se llama función cóncava. De igual manera, si se sustituye ≤ por ≥, con lo que la función tiene siempre una curvatura "hacia arriba" (o no tiene curvatura), se llama función convexa. (Así, una función lineal no es tanto cóncava como convexa). En la figura 14.8 se pueden ver ejemplo de esto. Nótese que la figura 14.7 ilustra una función que no es cóncava, ni convexa pues alterna sus curvaturas hacia arriba y hacsia abajo.
Las funciones de las variables múltiples también se pueden caracterizar como cóncavas o convexas si su curvatura es siempre hacia abajo o hacia arriba. Por ejemplo, considérese una función que consiste en una suma de términos. Si todos los términos son cóncavos (se puede verificar que lo sea, con su segunda derivada cuando el término incluye nada más una de las variables), entonces la función es cóncava. De manera similar, la función es convexa i todos los términos son convexos. Estas definiciones intuitivas se fundamentan en términos precisos que, junto con un poco de profundización en los conceptos, se presentanen el apéndice I.
Las funciones de las variables múltiples también se pueden caracterizar como cóncavas o convexas si su curvatura es siempre hacia abajo o hacia arriba. Por ejemplo, considérese una función que consiste en una suma de términos. Si todos los términos son cóncavos (se puede verificar que lo sea, con su segunda derivada cuando el término incluye nada más una de las variables), entonces la función es cóncava. De manera similar, la función es convexa i todos los términos son convexos. Estas definiciones intuitivas se fundamentan en términos precisos que, junto con un poco de profundización en los conceptos, se presentanen el apéndice I.
domingo, 13 de septiembre de 2015

sábado, 12 de septiembre de 2015
Ilustración gráfica de problema de programación no lineal (IV)
En general, los algoritmos de programación no lineal no pueden distinguir entre un máximo local y un máximo global (excepto si encuentran otro máximo local mejor), por lo que es determinante conocer cuándo se garantiza que un máximo local es un máximo global en la región factible. Recuérdese que en Cálculo, cuando se maximiza una función ordinaria (doblemente diferenciable) de una sola variable f(x) sin restricciones, eta garantía está dada si
d²f/dx² ≤ para toda x
d²f/dx² ≤ para toda x
viernes, 11 de septiembre de 2015
Ilustración gráfica de problema de programación no lineal (III)
Por otro lado, sí
Z = 54x1 - 9x1² + 78x2 - 13x2²
entonces la solución óptima resulta (x1, x2) = (3,3), que se encuentra dentro de la frontera de la región factible. (SE puede comprobar que esta solución es óptimasi se usa el Cálculo para derivarla como un máximo global no restringido; como también satisface las restricciones, debe ser óptima para el problema restringido). Por lo tanto, es necesario que un algoritmo general para resolver problemas de este tipo tome en cuenta toda las soluciones en la regiónn factible y no sólo aquéllas que están sobre la frontera.
Otra complicación que surge en la programación no líneal es que un máximo local no necesariamente es un máximo global (la solución óptima global). Por ejemplo, considérese la función de una sola variable graficada en la figura 14.7. En el intervalo 0 ≤ x ≤ 5, esta función tiene tres máximos locales, x = 0, x = 2, x = 4, pero sólo uno de estos, x = 4, e un máximo global. (De igual manera, existen mínimo locales en x = 1, 3 y 5, pero sólo x = 5 es un mínimo global)
Z = 54x1 - 9x1² + 78x2 - 13x2²
entonces la solución óptima resulta (x1, x2) = (3,3), que se encuentra dentro de la frontera de la región factible. (SE puede comprobar que esta solución es óptimasi se usa el Cálculo para derivarla como un máximo global no restringido; como también satisface las restricciones, debe ser óptima para el problema restringido). Por lo tanto, es necesario que un algoritmo general para resolver problemas de este tipo tome en cuenta toda las soluciones en la regiónn factible y no sólo aquéllas que están sobre la frontera.
Otra complicación que surge en la programación no líneal es que un máximo local no necesariamente es un máximo global (la solución óptima global). Por ejemplo, considérese la función de una sola variable graficada en la figura 14.7. En el intervalo 0 ≤ x ≤ 5, esta función tiene tres máximos locales, x = 0, x = 2, x = 4, pero sólo uno de estos, x = 4, e un máximo global. (De igual manera, existen mínimo locales en x = 1, 3 y 5, pero sólo x = 5 es un mínimo global)
jueves, 10 de septiembre de 2015
Ilustración gráfica de problema de programación no lineal (II)
Ahora supóngase que la restricciones lineales de la sección 3.1 se conservaran sin cambio, pero que la función objetivo se hace no lineal. Por ejemplo, si

miércoles, 9 de septiembre de 2015
Ilustración gráfica de problema de programación no lineal (I)
Cuando un problema de programación no lineal tiene sólo una o dos variables, se puede representar en una gráfica en forma muy parecida al ejemplo de la Wyndor Glass Co., para programación lineal, en la sección 3.1. Se verán unos cuantos ejemplos, ya que una representación gráfica de este tipo proporciona una visión global de las propiedades de las soluciones óptima de programación lineal y no lineal. Con el fin de hacer hincapié en las diferencias se usarán algunas variaciones no lineales del problema de la Wyndor Glass Co.
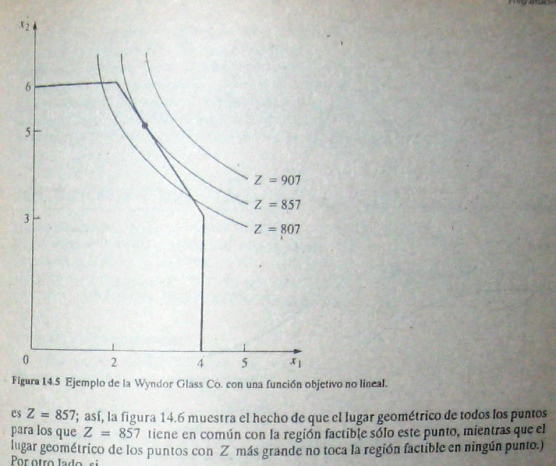
La figura 14.5 muestra lo que ocurre con este problema si los únicos cambios que se hacen al modelo de la sección 3.1 son que la segunda y tercera restricciones se sustituyen por la restricción no lineal 9x1² + 5x2² ≤ 216. Compárense las figuras 14.5 y 3.3. La solución óptima sigue siendo(x1, x2) = (2,6). Además, todavía se encuentra sobre la frontera de la región factible, pero no es una solución en un vértice. La solución óptima pudo haber sino una solución factible en un vértice con una función objetivo diferente (verifíquese Z = 3x1 + x2), pero el hecho de que no necesita serlo significa que ya no se puede aprovechar la gran simplificación utilizada en programación lineal que permite limitar la búsqueda de una solución óptima nada más a la olucione factibles en los vértices.
La figura 14.5 muestra lo que ocurre con este problema si los únicos cambios que se hacen al modelo de la sección 3.1 son que la segunda y tercera restricciones se sustituyen por la restricción no lineal 9x1² + 5x2² ≤ 216. Compárense las figuras 14.5 y 3.3. La solución óptima sigue siendo(x1, x2) = (2,6). Además, todavía se encuentra sobre la frontera de la región factible, pero no es una solución en un vértice. La solución óptima pudo haber sino una solución factible en un vértice con una función objetivo diferente (verifíquese Z = 3x1 + x2), pero el hecho de que no necesita serlo significa que ya no se puede aprovechar la gran simplificación utilizada en programación lineal que permite limitar la búsqueda de una solución óptima nada más a la olucione factibles en los vértices.
martes, 8 de septiembre de 2015
Selección de una cartera de inversiones riesgosa (IV)
Uno de los defectos de esta formulación es que, como R(x) y V(x) son de alguna manera inconmesurables, es relativamente difícil elegir un valor apropiado de β. Entonces, en lugar de terminar el proceso con una elección de β, es común que se use programación (no lineal) paramétrica para generar la solución óptima como una función de β en un intervalo amplio de valores; el siguiente paso consiste en analizar los valores de R(x) y V(x) para estas soluciones que son óptimas para algún valor de β y después elegir la solución que dé el mejor trueque entre estas dos cantidades. Con frecuencia se hace referencia a este procedimiento como la generación de soluciones sobre la frontera eficiente de la gráica de dos dimensiones de los puntos (R(x), V(x)) para toda las x factibles. La razón es que el punto (R(x), V(x)) para una x óptima (para alguna β) se encuentra sobre la frontera (límite) de los puntos factibles. Más aún, cada punto x es eficiente, en el sentido de que ninguna otra solución factible esrá cuando menos igualmente buena con una medida (R o V) y estrictamente mejor con la otra medida (V más pequeña o R más grande).
lunes, 7 de septiembre de 2015
Selección de una cartera de inversiones riesgosa (III)
El modelo de programación no lineal completo puede ser
 en donde Pj es el precio de cada acción tipo j y B es la cantidad de dinero presupuestada para la cartera. Si se hacen ciertas suposiciones sobre la función de utilidad del inversionista (medida del valor relativo para el inversionista de lo distintos rendimientos totales), se puede demostrar que una solución óptima para este modelo de programación no lineal maximiza la utilidad esperada del inversionista.
en donde Pj es el precio de cada acción tipo j y B es la cantidad de dinero presupuestada para la cartera. Si se hacen ciertas suposiciones sobre la función de utilidad del inversionista (medida del valor relativo para el inversionista de lo distintos rendimientos totales), se puede demostrar que una solución óptima para este modelo de programación no lineal maximiza la utilidad esperada del inversionista.

domingo, 6 de septiembre de 2015
Selección de una cartera de inversiones riesgosa (II)
Se puede formular un modelo de programación no lineal para este problema de la siguiente manera. Supóngase que se están tomando en cuenta n tipos de acciones para incluirlas en la cartera; las variables de decisión xj (j = 1,2,....., n) representan el número de acciones j que van se van a incluir. SEan μj y σjj la media y la variancia (estimadas) del rendimiento sobre cada acción del tipoj, en donde σjj mide el riesgo de estas acciones. Para i =1,2,....., n (i ≠ j), sea σij la covariancia del rendmiento sobre una acción de cada tipo i y j. (Como sería difícil estimar todas las σij, lo usual es hacer ciertes suposiciones sobre el comportamiento del mercado que permitan calcular σij directamente, a partir de σii y σjj.) Entonces, el valor esperado R(x) y la variancia V(x) del rendmiento total de la cartera completa son


sábado, 5 de septiembre de 2015
Selección de una cartera de inversiones riesgosa (I)
ES ahora una práctica común entre los administradores de grandes carteras de inversión usar, como una guía, model de computadora basados en parte en programación no lineal. Como los inversionistas se preocupan tanto por el rendimiento esperado (ganancia), como por el riesgo asociado con su inversión, la programación no lineal se usa para determinar una cartera que, con ciertas suposiciones, proporcione un trueque óptimo entre estos dos factores.

viernes, 4 de septiembre de 2015

jueves, 3 de septiembre de 2015
Problema de transporte con descuentos por volumen en los precios de embarque
Como se ilustró en el ejemplo de la P & T Co., en la sección 7.1, una aplicación común del problema de transporte es determinar un plan óptimo para mandar bienes desde varios orígenes hasta varios destinos, dadas las restricciones de recursos y demanda, con el fin de minimizar el costo total de transporte. En el capítulo 7 se supuso que el costo por unidad enviada de un origen a un destino dados es fijo, independientemente de la cantidad mandada. En la realidad, este costo puede no ser fijo. A veces se dispone de descuentos por volumen para cantidades grandes, con lo que el costo marginal de mandar una unidad más puede seguir un patrón como el que se muestra en la figura 14.3. El costo que resulta al embarcar x unidades está dado entonces por una función no lineal C(x) que es una función lineal por partes con pendiente igual al costo marginal, como la que se muestra en la figura 14.4. En consecuencia, si cada combinación de origen y destino tiene una función de costos similar, es decir, si el costo de mandar xij unidades del origen i (i = 1,2,.....m) al destino j (j = 1,2,.....,m) está dado por una función no lineal Cij(xij), entonces la función objetivo global que se va a minimizar es:

miércoles, 2 de septiembre de 2015
El problema de la mezcla de productos con elasticidad en los precios (II)
Otra razón por la que pueden surgir no linealidades en la función objetivo es que los costos marginales al producir otra unidad más de un producto dado pueden variar con el nivel de producción. Por ejemplo, el costo marginal puede decrecer cuando aumente el nivel de producción, gracias al efecto de una curva de aprendizaje (mayor eficiencia con más experiencia). Por otro lado, pueden aumentar a causa de ciertas medidas especiales, como tiempos extra o instalaciones de producción más costosas, necesarias para aumentar la producción.
La no linealidad también puede surgir en las funciones de restricción gi(x) en forma bastante parecida. Por ejemplo, si existe una restricción de presupuesto sobre el costo total de producción, la función de costo será no lineal si el costo marginal de producción varía como se acaba de describir. Para restricciones sobre otro tipo de recursos, gi(x) será no lineal siempre que el uso del recurso correspondiente no sea estrictamente proporcional a los niveles de los respectivos productos.
martes, 1 de septiembre de 2015

lunes, 31 de agosto de 2015
El problema de la mezcla de productos con elasticidad en los precios (I)
En problemas de mezcla de productos, como el de la Wyndor Glass Co. de la sección 3.1 la meta es determinar la mezcla óptima de niveles de producción para los productos de una empresa, dadas las limitaciones sobre los recursos necesarios para producirlos, con el fin de maximizar la ganancia total de la empresa. En algunos casos existe una ganancia unitaria fija asociada a cada producto, con lo que la función objetivo que se obitiene es lineal. Sin embargo, en muchos problemas de mezclas de productos, ciertos factores introducen no linealidades en la función objetivo. Por ejemplo, un fabricante grande puede encontrar precios elásticos mediante los cuales la cantidad que se puede vender de un producto ya en relación inversa con el precio que se cobra. Así la curva precio-demanda puede parecerse a la que se muestra en la figura 14.1, en donde p(x) es el precio que se necesita para poder vender x unidades. Si el costo unitario de producir el artículo está fijo en c (véase la línea punteada en la figura 14.1), entonces la ganancia de la empresa por producir y vender x unidades está dada por una función no lineal.

domingo, 30 de agosto de 2015
Algunas aplicaciones
Los siguientes ejemplos ilustran unos cuantos de los muchos tipos importantes de problemas a los que se ha aplicado la programación no lineal.
sábado, 29 de agosto de 2015
Programación no lineal (II)
No se dispone de un algortimo que resuelva todos los problemas especificos que se ajustan a este formato. Se han hecho grandes logros en lo que se refiere a algunos importantes casos especiales de este problema, haciendo algunas suposiciones sobre las funciones, y la investigación sigue muy activa. Esta área es amplia y aquí no se cuenta con el espacio suficiente para un estudio completo. Se presentarán algunos ejemplos de aplicación y después se introducirán algunas ideas básicas para resolver ciertos tipos importantes de problemas de programación no lineal.
viernes, 28 de agosto de 2015
Programación no lineal (I)
El papel fundamental que juega la programación lineal en la investigación de operaciones se refleja en el hecho de que es el tema central de siete capítulos de este libro, además de que se aborta en algunos otros. Una suposición importante de programación lineal es que todas sus funciones (función objetivo y funciones de restricción) son lineales. Aunque, en esencia, esta suposición se cumple para muchos problemas prácticos, es frecuente que no sea así. De hecho, muchos economistas han encontrado que cierto grado de no linealidad es la regla, y no la excepción, en los problemas de planeación económica, por lo cual, muchas veces es necesario manejar problemas de programación no lineal, que es el área que se examinará en seguida.
De una manera general, el problemade programación no lineal consiste en encontrar x = (x1, x2,......xn) para
Maximizar f(x).
sujeta a gi(x) ≤ bi, para i = 1,2,......m
x ≥ 0,
en donde f(x) y las gi(x) son funciones dadas de n variables de decisión.
De una manera general, el problemade programación no lineal consiste en encontrar x = (x1, x2,......xn) para
Maximizar f(x).
sujeta a gi(x) ≤ bi, para i = 1,2,......m
x ≥ 0,
en donde f(x) y las gi(x) son funciones dadas de n variables de decisión.
jueves, 27 de agosto de 2015
Conclusión Programación Entera (III)
Para vencer estas dificultades de redondeo, se ha logrado un progreso considerable en él desarrollo de algoritmos heurísticos eficientes. Incluso con problemas de PE muy grandes, estos algoritmos encontrarán con rapidez soluciones factibles muy buenas que no son necesariamente óptimas, pero que casi siempre son mejores que las que se encuentran por redondeo.
Recientemente se han llevado a cabo muchas investigaciones con el fin de desarrollar algoritmos para programación entera no lineal, área cuyo estudio continúa muy activo.
Recientemente se han llevado a cabo muchas investigaciones con el fin de desarrollar algoritmos para programación entera no lineal, área cuyo estudio continúa muy activo.
miércoles, 26 de agosto de 2015
Conclusión Programación Entera (II)
Aparentemente ha surgido una nueva etapa en la metodología de solución de problemas de PE, con una serie de artículos publicados en la década de 1980. El nuevo enfoque algorítmico involucra la combinación de preprocesado automático del problema, generación de cortaduras y las técnicas de ramificación y acotamiento. Continúa la investigación en esta área.
A veces los problemas prácticos de PE son tan grandes que no se pueden resolver ni con los últimos algoritmos. En estos casos, es común aplicar el método símplex nada más a la soltura de PL y después redondear la solución a una solución entera factible. Este enfoque no suele ser satisfactorio porque puede ser difícil (o imposible) encontrar una solución etera factible de esta manera. Y aun encontrándola, puede estar muy alejada del óptimo. Esto es cierto en especial cuando se manejan variables binarias e incluso variables enteras generales con valores pequeños.
A veces los problemas prácticos de PE son tan grandes que no se pueden resolver ni con los últimos algoritmos. En estos casos, es común aplicar el método símplex nada más a la soltura de PL y después redondear la solución a una solución entera factible. Este enfoque no suele ser satisfactorio porque puede ser difícil (o imposible) encontrar una solución etera factible de esta manera. Y aun encontrándola, puede estar muy alejada del óptimo. Esto es cierto en especial cuando se manejan variables binarias e incluso variables enteras generales con valores pequeños.
martes, 25 de agosto de 2015
Conclusión Programación Entera (I)
Los problemas de programación entera surgen con frecuencia cuando los valores de algunas o todas las varibles de decisión deben restringirse a valores enteros. Existen también muchas aplicaciones que necesitan decisiones de sí o no - incluyendo las relaciones combinatorias que se puedan expresar en términos de tales decisiones - que se pueden representar por variables binarias (0-1). Estos problemas son más difçiles de lo que serían sin la restricción de valores enteros, de manera que los algoritmos disponibles para programación entera, en general, son mucho menos eficientes que el método símplex. Los factores que determinan el tiempo de cálculo son el número de variables enteras y la estructura del problema. Para un número fijo de variables enteras, casi siempre es más fácil resolver problemas de PEB que problemas con variables enteras generale, pero agregar variables continuas (PEM) puede no significar un incremento en el tiempo de cálculo. Para problemas especiales de PEB que contienen alguna estructura especial que se puede aprovechar mediante un algoritmo especial, es posible resolver problemas muy grandes (muy por encima de mil variables binarias) en forma rutinaria. Puede ser que otros problemas mucho más pequeños sin estructura especial no e puedan resolver.
En la actualidad es común que se disponga de paquetes de computadora para algoritmos de programación entera en el software de programación matemática. EStos algoritmos casi siempre se basan en la técnica de ramificación y acotamiento o en alguna variación de ésta.
En la actualidad es común que se disponga de paquetes de computadora para algoritmos de programación entera en el software de programación matemática. EStos algoritmos casi siempre se basan en la técnica de ramificación y acotamiento o en alguna variación de ésta.
lunes, 24 de agosto de 2015
Programación Entera Desarrollos recientes (IX)
Irónicamente, los primeros algoritmos desarrollados para programación entera binaria, incluso el celebrado algoritmo que publicó Ralph Gomory en 1958, estaban basados en cortadura (excepto para algunos tipos especiales de problemas). No obstante, estos algoritmos se apoyaban únicamente en las cortaduras. Ahora se sabe que una combinación acertada de la cortaduras y de la técnicas de ramificación y acotamiento (junto con el preprocesado automático del problema) proporciona un enfoque algorítmico poderoso para resolver problemas de PEB de gran escala.
domingo, 23 de agosto de 2015
Programación Entera Desarrollos recientes (VIII)
Esta nueva restricción es una cortadura "Corta" la solución óptima de la soltura de PL (5/6, 1, 0, 1), pero no elimina ninguna solución entera factible. Si se agrega tan sólo esta cortadura al modelo original, se mejora el desempeño de algoritmo de ramificación y acotamiento de PEB de la sección 13.4 (véase la figura 13.7) en dos formas. Primero, la solución óptima para la nueva (y más estrecha) soltura de PL sería (1, 1, 1/5, 0), con Z = 15(1/5) de manera que la cotas para los nodos de todo el problema, x1 = 1 y x2 = 1, serían ahora de 15 en lugar de 16. Segundo, se necesitaría una iteración menos, porque la solución óptima de la soltura de PL en el nodo x3 = 0 sería (1, 1, 0, 0), que proporciona una nueva solución de apoyo con Z* = 14. Por tanto, en la tercera iteración (véase la figura 13.6) se sondearía este nodo por la prueba 3 y el nodo x2 = 0 se sondearía por la prueba 1, indicando que esta nueva solución de apoyo es la solución óptima para el problema de PEB original.
El nuevo enfoque algorítmico presentado en las referencias selectas 1,4 y 13 implica la generación de muchas cortaduras en forma parecida antes de aplicar las técnicas de ramificación y acotamiento. Los resultados al incluir cortaduras pueden ser importantes para estrechar las solturas de PL. Por ejemplo, para el problema de prueba con 2756 variables binarias del artículo de 1983, se generaron 326 cortaduras. El resultado fue que la distancia entre el valor de Z de la solución óptima de la soltura de PL del problema completo de PEB y el valor de Z de la solución óptima del problema se redujo en un 98%. En casi la mitad de los problemas se obtuvieron resultados similares.
El nuevo enfoque algorítmico presentado en las referencias selectas 1,4 y 13 implica la generación de muchas cortaduras en forma parecida antes de aplicar las técnicas de ramificación y acotamiento. Los resultados al incluir cortaduras pueden ser importantes para estrechar las solturas de PL. Por ejemplo, para el problema de prueba con 2756 variables binarias del artículo de 1983, se generaron 326 cortaduras. El resultado fue que la distancia entre el valor de Z de la solución óptima de la soltura de PL del problema completo de PEB y el valor de Z de la solución óptima del problema se redujo en un 98%. En casi la mitad de los problemas se obtuvieron resultados similares.
sábado, 22 de agosto de 2015
Programación Entera Desarrollos recientes (VII)
Para ilustrar la cortadura, considérese el problema de programación entera pura de la California Manufacturing Co. que e presentó en la sección 13.1 y que se usó para ilustrar la técnica de ramificación y acotamiento de PEB en la sección 13.4. La solución óptima de su soltura de PL está dada en la figura 13.3 como (x1, x2, x3, x4) = (5/6, 1, 0, 1). Una de las restricciones funcionales es
6x1 + 3x2 + 5x3 + 2x4 ≤ 10
Ahora nótese que las restricciones binarias y esta restricción juntas implican que
x1 + x2 +x4 ≤ 2.
6x1 + 3x2 + 5x3 + 2x4 ≤ 10
Ahora nótese que las restricciones binarias y esta restricción juntas implican que
x1 + x2 +x4 ≤ 2.
viernes, 21 de agosto de 2015
Programación Entera Desarrollos recientes (VI)
Hacerlo tiene la ventaja importante de estrechar la soltura de PL (lo que elimina algunas de sus soluciones factibles) sin eliminar ninguna solución factible del problema de PEB. Otra técnica es preparar un "gatillo" que va a fijar el valor de una o más variables, después que se ha dado cierto valor a otra variable durante el desarrollo del algoritmo. Por ejemplo, para el grupo de variables que representan un conjunto de alternativas mutuamente excluyentes, en cuanto una de las variables se iguala a 1, el resto se puede fijar 0. Un gatillo de este tipo se puede preparar también para las restricciones que representan decisiones continuas y para otras restricciones con forma similar.
Se ha comprobado que el uso de la computadora para llevar a cabo estas ideas y otras parecidas en forma automática es de gran ayuda para acelerar un algoritmo. Sin embargo, una técnica todavía más importante es la generación de planos cortantes. Una cortadura para un problema de PE es una nueva restricción que elimina algunas soluciones factibles de la soltura de PL original, incluso su solución óptima. El propósito de agregar una nueva restricción con esta propiedad es estrechar la soltura de PL, estrechando con esto la cota obtenida en el paso de acotamiento de la técnica de ramificación y acotamiento. Al estrechar la soltura de PL se incrementa la posiblidad de que su solución óptima sea factible (y por lo tanto óptima) para el problema de PE, con lo que e mejoraría la prueba de sondeo 3.
Se ha comprobado que el uso de la computadora para llevar a cabo estas ideas y otras parecidas en forma automática es de gran ayuda para acelerar un algoritmo. Sin embargo, una técnica todavía más importante es la generación de planos cortantes. Una cortadura para un problema de PE es una nueva restricción que elimina algunas soluciones factibles de la soltura de PL original, incluso su solución óptima. El propósito de agregar una nueva restricción con esta propiedad es estrechar la soltura de PL, estrechando con esto la cota obtenida en el paso de acotamiento de la técnica de ramificación y acotamiento. Al estrechar la soltura de PL se incrementa la posiblidad de que su solución óptima sea factible (y por lo tanto óptima) para el problema de PE, con lo que e mejoraría la prueba de sondeo 3.
jueves, 20 de agosto de 2015
Programación Entera Desarrollos recientes (V)
El procesado automático del problema incluye una "inspección por computadora" de la formulación del problema de programación entera proporcionada por el usuario, con el fin de detectar algunas reformulaciones que hacen que el problema se resuelva con más rapidez, sin eliminar ninguna solución factible. Algunas ideas son muy sencillas, como se ilustrará con variables binarias puras. Es posible fijar el valor de una variable en 0 o en 1 debido a alguna restricción, por ejemplo,
3x1 + 2x2 ≤ 2 ⇒ x1 = 0
3x3 - 2x4 ≤ -1 ⇒ x3 = 0 y x4 = 1
de manera que se puede eliminar la variable del modelo (después de sustituir su valor fijo). una restricción funcional puede ser redundante a las restriciones binarias, por ejemplo,
3x1 + 2x2 ≤ 6,
y puede eliminarse. Es posible estrechar una restricción funcional reduciendo algunos de sus coeficientes, debido a las restricciones binarias, por ejemplo,
4x1 + 5x2 + x3 ≥ 2 ⇒ 2x1 + 2x2 + x3 ≥ 2
3x1 + 2x2 ≤ 2 ⇒ x1 = 0
3x3 - 2x4 ≤ -1 ⇒ x3 = 0 y x4 = 1
de manera que se puede eliminar la variable del modelo (después de sustituir su valor fijo). una restricción funcional puede ser redundante a las restriciones binarias, por ejemplo,
3x1 + 2x2 ≤ 6,
y puede eliminarse. Es posible estrechar una restricción funcional reduciendo algunos de sus coeficientes, debido a las restricciones binarias, por ejemplo,
4x1 + 5x2 + x3 ≥ 2 ⇒ 2x1 + 2x2 + x3 ≥ 2
miércoles, 19 de agosto de 2015
Programación Entera Desarrollos recientes (IV)
Aunque está más allá del alcance de este libro describir con detalle el nuevo enfoque algorítmico, se dará una idea global breve. ( Se anima al lector a que la las referencias 1, 4 y 13 para mayor información).
Este enfoque utiliza una combinación de los tres tipos de técnicas: 1) preprocesado automático del problema, 2) generación de planos cortantes o cortaduras y 3) técnicas de ramificación y acotamiento. El lector está familiarizado con la técnicas de ramificación y acotamiento y no se profundizará más en las versiones más elaboradas que se incorporan aquí. A continuación e da una introducción conceptual sobre los otros dos tipo de técnicas que usan.
martes, 18 de agosto de 2015
Programación Entera Desarrollos recientes (III)
Es necesario agregar una nota de precaución. No está claro qué tan consistente es el éxito de este enfoque algorítmico al resolver una amplia variedad de problemas de este tipo de gran escala. Los problemas más grandes de PEB pura que se han resuelto tenían matrices A no densas, es decir, el procentaje de coeficientes en las restricciones funcionales, que eran distintos de cero, era bastante pequeño (quizá menos del 5%). De hecho, el enfoque depende fuertemente de esta densidad. (Por fortuna, este tipo de poca densidad es frecuente en los problemas prácticos) Más aún, existen otros factores importantes, además de la densidad y el tamaño que afectan la dificultad de la solución de los problemas de PE. Parece que las formulaciones de PE de tamaño bastante grande deben todavía hacerse con mucho cuidado.
Por otro lado, cada nuevo cambio algorítmico en investigación de operaciones genera siempre una renovación en la actividad de investigación para desarrollar y refinar el nuevo enfoque. Sin duda se verán más frutos de la intensificación de esta actividad en programación entera durante la siguiente década. Quizá a través de la investigación se puedan disminuir las diferencias que existen en cuanto a la eficiencia entre lo algoritmos de programación entera y los de programación líneal.
Por otro lado, cada nuevo cambio algorítmico en investigación de operaciones genera siempre una renovación en la actividad de investigación para desarrollar y refinar el nuevo enfoque. Sin duda se verán más frutos de la intensificación de esta actividad en programación entera durante la siguiente década. Quizá a través de la investigación se puedan disminuir las diferencias que existen en cuanto a la eficiencia entre lo algoritmos de programación entera y los de programación líneal.
lunes, 17 de agosto de 2015
Programación Entera Desarrollos recientes (II)
Más tarde llegó el siguiente cambio, a mediados de la década de 1981, según se publicó en tres artículos en 1983, 1985 y 1987. (Véanse las referencias 1, 4 y 13). En el artículo de 1983, Harlan Crowder, Ellis Johnson y Manfred Padberg presentaron un nuevo enfoque algoritmico para resolver problemas de PEB pura que había resuelto con éxito problemas sin una estructura especial aparente, con hasta 2756 variables! Este artículo ganó el Lancaster Prize otorgado por la Operations Research Society of America a la publicación más notable en investigación de operaciones durante 1983. En el artículos de 1985, Ellis Johnson, Michael Kostreva y Uwe Suhl refinaron este enfoque algorítmico.
Sin embargo, estos dos artículos se limitana PEB pura. ES bastante común que en los problemas de PE que surgen en la práctica todas las variables restringidas a valores enteros sean binarias, pero muchos de estos problemas son de PEBmixta. Lo que e necesitaba con desesperación era una forma de extender este mismo tipo de algoritmo a la PEBmixta. Esto ocurrió en el artículo de 1987 publicado por Tony Van Roy y Laurence Wolsey de Bélgica. Una vez más, se resolvían con éxito problemas de tamaño muy grande (hasta cerca de mil variables binarias y un gran número de variable continuas). Una vez más, este artículo ganó un prestigiado premio, el Orchard-Hays Price otorgado por la Mathematical Programming Society.
Sin embargo, estos dos artículos se limitana PEB pura. ES bastante común que en los problemas de PE que surgen en la práctica todas las variables restringidas a valores enteros sean binarias, pero muchos de estos problemas son de PEBmixta. Lo que e necesitaba con desesperación era una forma de extender este mismo tipo de algoritmo a la PEBmixta. Esto ocurrió en el artículo de 1987 publicado por Tony Van Roy y Laurence Wolsey de Bélgica. Una vez más, se resolvían con éxito problemas de tamaño muy grande (hasta cerca de mil variables binarias y un gran número de variable continuas). Una vez más, este artículo ganó un prestigiado premio, el Orchard-Hays Price otorgado por la Mathematical Programming Society.
domingo, 16 de agosto de 2015
Programación Entera Desarrollos recientes (I)
La programación entera ha sido un área emocionante de investigación de operaciones durante los últimos años por los dramáticos adelantos hechos en su metodología de solución.
Para dar una mejor perspectiva sobre este progreso, considérense los antecedentes históricos. A fines de la década de 1960 y principios de la de 1970 hubo un cambio grande con el desarrollo y refinamiento del enfoque de ramificación y acotamiento. Después, todo siguió igual; se podían resolver en forma muy eficiente problemas relativamente pequeños (muy por debajo de las cien variables) pero aún un pequeño aumento en el tamaño del problema podía causar una explosión en el tiempo de cálculos más allá de los límites factibles. Se hacían pocos progresos para vencer este crecimiento exponencial en el tiempo de computación; cuando el tamaño del problema aumentaba, muchos problemas importantes que surgían en la práctica no se podían resolver.
Para dar una mejor perspectiva sobre este progreso, considérense los antecedentes históricos. A fines de la década de 1960 y principios de la de 1970 hubo un cambio grande con el desarrollo y refinamiento del enfoque de ramificación y acotamiento. Después, todo siguió igual; se podían resolver en forma muy eficiente problemas relativamente pequeños (muy por debajo de las cien variables) pero aún un pequeño aumento en el tamaño del problema podía causar una explosión en el tiempo de cálculos más allá de los límites factibles. Se hacían pocos progresos para vencer este crecimiento exponencial en el tiempo de computación; cuando el tamaño del problema aumentaba, muchos problemas importantes que surgían en la práctica no se podían resolver.
sábado, 15 de agosto de 2015
Ejemplo Resumen del algoritmo de ramifiación y acotamiento de PEM (X)
El subproblema 6 se sondea de inmediato con la prueba 2. El subproblema 5 también se puede sondear con la prueba 3, porque la solución óptima de esta soltura de PL tiene valores enteros (x1`= 0, x2 = 0, x3 = 2) para las tres variables restringidas a enteros. (No importa que x4 = 1/2, ya que x4 no está restringida a enteros). Esta solución factible para el problema original se convierte en la primera solución de apoyo (incumbente):
Incumbente = (0, 0, 2, 1/2) con Z* = 13(1/2)
Con esta Z* se vuelve a realizar la prueba de sondeo 1 al otro subproblema (subproblema 4) y pasa la prueba, ya que su cota de 12(1/6) es ≤ Z*.
Esta iteración tuvo éxito en sondear de la tres maneras posibles. Lo que es más, ya no hay subproblemas restantes, por lo tanto la solución incumbente actual es óptima.
Solución óptima = (0, 0, 2, 1/2), con Z* = 13(1/2).
EStos resultados se resumen en el árbol de soluciones de la figura 13.10.
Incumbente = (0, 0, 2, 1/2) con Z* = 13(1/2)
Con esta Z* se vuelve a realizar la prueba de sondeo 1 al otro subproblema (subproblema 4) y pasa la prueba, ya que su cota de 12(1/6) es ≤ Z*.
Esta iteración tuvo éxito en sondear de la tres maneras posibles. Lo que es más, ya no hay subproblemas restantes, por lo tanto la solución incumbente actual es óptima.
Solución óptima = (0, 0, 2, 1/2), con Z* = 13(1/2).
EStos resultados se resumen en el árbol de soluciones de la figura 13.10.
viernes, 14 de agosto de 2015
Ejemplo Resumen del algoritmo de ramifiación y acotamiento de PEM (IX)
Iteración 3
De los dos subproblemas restantes (3 y 4) que se crearon al mismo tiempo, se selecciona el que tiene la cota más grande (subproblema 3, con 14(1/6) > 12(1/6) para la siguiente ramificación). Como x1 = 5/6 tiene un valor no entero en la solución óptima de la soltura de PL de su subproblema, x1 se convierte en la variable de ramificación. (Obsérvese que x1 es ahora una variable de ramificación recurrente, pues también se seleccionó en la iteración 1.) Esto conduce a los siguientes subproblemas:

jueves, 13 de agosto de 2015
Ejemplo Resumen del algoritmo de ramifiación y acotamiento de PEM (VIII)
Al resolver las solturas de PL se obtienen los siguientes resultados:
Soltura de PL del subproblema 3: (x1, x2, x3, x4) = (5/6, 1, 11/6, 0), con Z = 14(1/6)
Cota para el subproblema 3: Z ≤ 14(1/6)
Soltura de PL del subproblema 4: (x1, x2, x3, x4) = (5/6, 2, 11/6, 0), con Z = 12(1/6)
Cota para el subproblema 4: Z ≤ 12(1/6)
Como ambas soluciones existen (soluciones factibles) y tienen valores no enteros para variables restringidas a enteros, ninguno de los subproblemas se sondea. (La prueba I no es operativa, puesto que todavía Z* = - ∞, hasta que se encuentre la primera solución de apoyo.)
El árbol de solución hasta este punto se da en la figura 13.9.
Soltura de PL del subproblema 3: (x1, x2, x3, x4) = (5/6, 1, 11/6, 0), con Z = 14(1/6)
Cota para el subproblema 3: Z ≤ 14(1/6)
Soltura de PL del subproblema 4: (x1, x2, x3, x4) = (5/6, 2, 11/6, 0), con Z = 12(1/6)
Cota para el subproblema 4: Z ≤ 12(1/6)
Como ambas soluciones existen (soluciones factibles) y tienen valores no enteros para variables restringidas a enteros, ninguno de los subproblemas se sondea. (La prueba I no es operativa, puesto que todavía Z* = - ∞, hasta que se encuentre la primera solución de apoyo.)
El árbol de solución hasta este punto se da en la figura 13.9.
miércoles, 12 de agosto de 2015
Ejemplo Resumen del algoritmo de ramifiación y acotamiento de PEM (VII)
Subproblema 4:
problema original más las restricciones adicionales:
x1 ≤ 1
x2 ≥ 2

Suscribirse a:
Entradas (Atom)